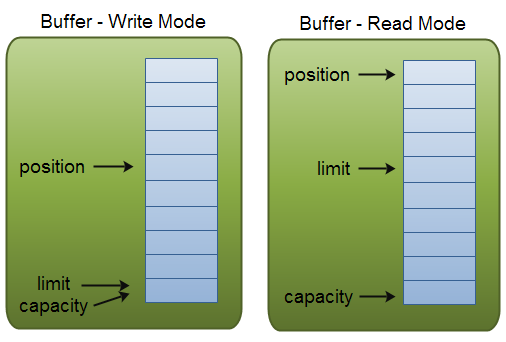
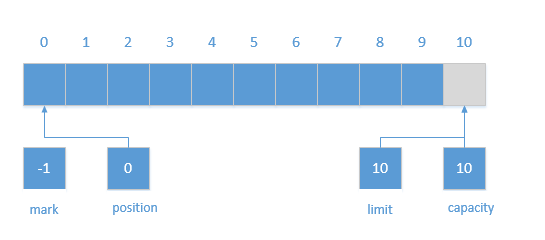
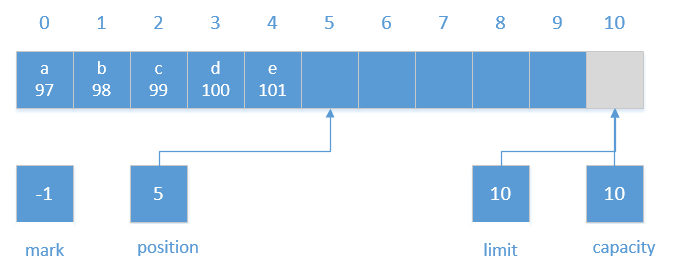
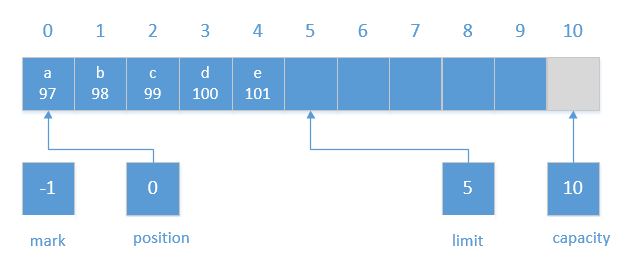
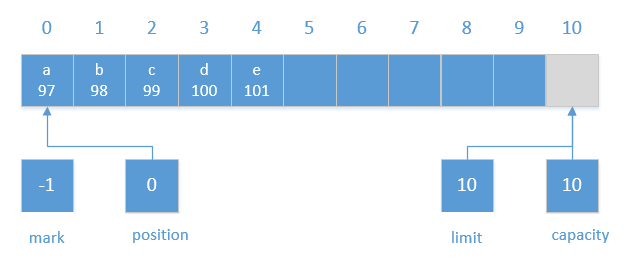
//java.nio.ByteBuffer#put(java.nio.ByteBuffer) public ByteBuffer put(ByteBuffer src){ if (src == this) throw createSameBufferException(); if (isReadOnly()) thrownew ReadOnlyBufferException(); int n = src.remaining(); if (n > remaining()) thrownew BufferOverflowException(); for (int i = 0; i < n; i++) put(src.get()); returnthis; } //java.nio.Buffer#remaining publicfinalintremaining(){ return limit - position; }
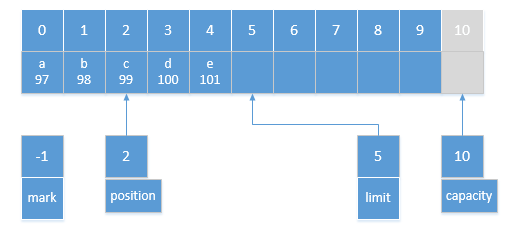
//java.nio.ByteBuffer#put(java.nio.ByteBuffer) public ByteBuffer put(ByteBuffer src){ if (src == this) throw createSameBufferException(); if (isReadOnly()) thrownew ReadOnlyBufferException(); int n = src.remaining(); if (n > remaining()) thrownew BufferOverflowException(); for (int i = 0; i < n; i++) put(src.get()); returnthis; } //java.nio.HeapByteBuffer#asReadOnlyBuffer public ByteBuffer asReadOnlyBuffer(){
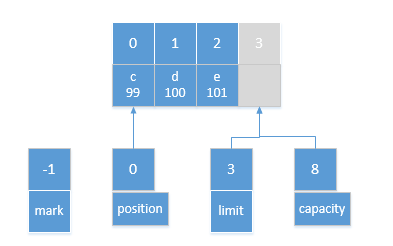
returnnew HeapByteBufferR(hb, this.markValue(), this.position(), this.limit(), this.capacity(), offset); } //java.nio.HeapByteBufferR#asReadOnlyBuffer //HeapByteBufferR下直接调用其duplicate方法即可,其本来就是只读的 public ByteBuffer asReadOnlyBuffer(){ return duplicate(); } //java.nio.DirectByteBuffer#asReadOnlyBuffer public ByteBuffer asReadOnlyBuffer(){
//java.nio.HeapByteBufferR#HeapByteBufferR protectedHeapByteBufferR(byte[] buf, int mark, int pos, int lim, int cap, int off) { super(buf, mark, pos, lim, cap, off); this.isReadOnly = true;
} //java.nio.DirectByteBufferR#DirectByteBufferR DirectByteBufferR(DirectBuffer db, int mark, int pos, int lim, int cap, int off) {
//sun.nio.ch.SelectorImpl#register @Override protectedfinal SelectionKey register(AbstractSelectableChannel ch, int ops, Object attachment) { if (!(ch instanceof SelChImpl)) thrownew IllegalSelectorException(); SelectionKeyImpl k = new SelectionKeyImpl((SelChImpl)ch, this); k.attach(attachment);
// register (if needed) before adding to key set implRegister(k);
// add to the selector's key set, removing it immediately if the selector // is closed. The key is not in the channel's key set at this point but // it may be observed by a thread iterating over the selector's key set. keys.add(k); try { k.interestOps(ops); } catch (ClosedSelectorException e) { assert ch.keyFor(this) == null; keys.remove(k); k.cancel(); throw e; } return k; }
// Disable the Nagle algorithm so that the wakeup is more immediate SinkChannelImpl sink = (SinkChannelImpl)wakeupPipe.sink(); (sink.sc).socket().setTcpNoDelay(true); wakeupSinkFd = ((SelChImpl)sink).getFDVal();
try { // Create secret with a backing array. ByteBuffer secret = ByteBuffer.allocate(NUM_SECRET_BYTES); ByteBuffer bb = ByteBuffer.allocate(NUM_SECRET_BYTES);
// Loopback address InetAddress lb = InetAddress.getLoopbackAddress(); assert(lb.isLoopbackAddress()); InetSocketAddress sa = null; for(;;) { // Bind ServerSocketChannel to a port on the loopback // address if (ssc == null || !ssc.isOpen()) { ssc = ServerSocketChannel.open(); ssc.socket().bind(new InetSocketAddress(lb, 0)); sa = new InetSocketAddress(lb, ssc.socket().getLocalPort()); }
// Establish connection (assume connections are eagerly // accepted) sc1 = SocketChannel.open(sa); RANDOM_NUMBER_GENERATOR.nextBytes(secret.array()); do { sc1.write(secret); } while (secret.hasRemaining()); secret.rewind();
// Get a connection and verify it is legitimate sc2 = ssc.accept(); do { sc2.read(bb); } while (bb.hasRemaining()); bb.rewind();
if (bb.equals(secret)) break;
sc2.close(); sc1.close(); }
// Create source and sink channels source = new SourceChannelImpl(sp, sc1); sink = new SinkChannelImpl(sp, sc2); } catch (IOException e) { try { if (sc1 != null) sc1.close(); if (sc2 != null) sc2.close(); } catch (IOException e2) {} ioe = e; } finally { try { if (ssc != null) ssc.close(); } catch (IOException e2) {} } } } }
// Access methods for fd structures voidputDescriptor(int i, int fd){ pollArray.putInt(SIZE_POLLFD * i + FD_OFFSET, fd); }
voidputEventOps(int i, int event){ pollArray.putShort(SIZE_POLLFD * i + EVENT_OFFSET, (short)event); } ... // Adds Windows wakeup socket at a given index. voidaddWakeupSocket(int fdVal, int index){ putDescriptor(index, fdVal); putEventOps(index, Net.POLLIN); } }
这里将wakeupSourceFd的POLLIN事件标识为pollArray的EventOps的对应的值,这里使用的是unsafe直接操作的内存,也就是相对于这个pollArray所在内存地址的偏移量SIZE_POLLFD * i + EVENT_OFFSET这个位置上写入Net.POLLIN所代表的值,即参考下面本地方法相关源码所展示的值。putDescriptor同样是这种类似操作。当sink端有数据写入时,source对应的文件描述符wakeupSourceFd就会处于就绪状态。
1 2 3 4 5 6 7 8 9 10 11
//java.base/windows/native/libnio/ch/nio_util.h /* WSAPoll()/WSAPOLLFD and the corresponding constants are only defined */ /* in Windows Vista / Windows Server 2008 and later. If we are on an */ /* older release we just use the Solaris constants as this was previously */ /* done in PollArrayWrapper.java. */ #define POLLIN 0x0001 #define POLLOUT 0x0004 #define POLLERR 0x0008 #define POLLHUP 0x0010 #define POLLNVAL 0x0020 #define POLLCONN 0x0002
classAllocatedNativeObject // package-private extendsNativeObject { /** * Allocates a memory area of at least {@code size} bytes outside of the * Java heap and creates a native object for that area. */ AllocatedNativeObject(int size, boolean pageAligned) { super(size, pageAligned); }
/** * Frees the native memory area associated with this object. */ synchronizedvoidfree(){ if (allocationAddress != 0) { unsafe.freeMemory(allocationAddress); allocationAddress = 0; } }
} //sun.nio.ch.NativeObject#NativeObject(int, boolean) protectedNativeObject(int size, boolean pageAligned){ if (!pageAligned) { this.allocationAddress = unsafe.allocateMemory(size); this.address = this.allocationAddress; } else { int ps = pageSize(); long a = unsafe.allocateMemory(size + ps); this.allocationAddress = a; this.address = a + ps - (a & (ps - 1)); } }
//sun.nio.ch.SelectorImpl#register @Override protectedfinal SelectionKey register(AbstractSelectableChannel ch, int ops, Object attachment) { if (!(ch instanceof SelChImpl)) thrownew IllegalSelectorException(); SelectionKeyImpl k = new SelectionKeyImpl((SelChImpl)ch, this); k.attach(attachment);
// register (if needed) before adding to key set implRegister(k);
// add to the selector's key set, removing it immediately if the selector // is closed. The key is not in the channel's key set at this point but // it may be observed by a thread iterating over the selector's key set. keys.add(k); try { k.interestOps(ops); } catch (ClosedSelectorException e) { assert ch.keyFor(this) == null; keys.remove(k); k.cancel(); throw e; } return k; } //sun.nio.ch.WindowsSelectorImpl#implRegister @Override protectedvoidimplRegister(SelectionKeyImpl ski){ ensureOpen(); synchronized (updateLock) { newKeys.addLast(ski); } }
// sun.nio.ch.WindowsSelectorImpl#doSelect @Override protectedintdoSelect(Consumer<SelectionKey> action, long timeout) throws IOException { assert Thread.holdsLock(this); this.timeout = timeout; // set selector timeout processUpdateQueue(); // <1> processDeregisterQueue(); // <2> if (interruptTriggered) { resetWakeupSocket(); return0; } // Calculate number of helper threads needed for poll. If necessary // threads are created here and start waiting on startLock adjustThreadsCount(); finishLock.reset(); // reset finishLock // Wakeup helper threads, waiting on startLock, so they start polling. // Redundant threads will exit here after wakeup. startLock.startThreads(); // do polling in the main thread. Main thread is responsible for // first MAX_SELECTABLE_FDS entries in pollArray. try { begin(); try { subSelector.poll(); // <3> } catch (IOException e) { finishLock.setException(e); // Save this exception } // Main thread is out of poll(). Wakeup others and wait for them if (threads.size() > 0) finishLock.waitForHelperThreads(); } finally { end(); } // Done with poll(). Set wakeupSocket to nonsignaled for the next run. finishLock.checkForException(); processDeregisterQueue(); // <4> int updated = updateSelectedKeys(action); // <5> // Done with poll(). Set wakeupSocket to nonsignaled for the next run. resetWakeupSocket(); // <6> return updated; }
/** * sun.nio.ch.WindowsSelectorImpl#processUpdateQueue * Process new registrations and changes to the interest ops. */ privatevoidprocessUpdateQueue(){ assert Thread.holdsLock(this);
// changes to interest ops while ((ski = updateKeys.pollFirst()) != null) { int events = ski.translateInterestOps(); int fd = ski.getFDVal(); if (ski.isValid() && fdMap.containsKey(fd)) { int index = ski.getIndex(); assert index >= 0 && index < totalChannels; pollWrapper.putEventOps(index, events); } } } }
//sun.nio.ch.PollArrayWrapper#putEntry // Prepare another pollfd struct for use. voidputEntry(int index, SelectionKeyImpl ski){ putDescriptor(index, ski.getFDVal()); putEventOps(index, 0); } //sun.nio.ch.WindowsSelectorImpl#growIfNeeded privatevoidgrowIfNeeded(){ if (channelArray.length == totalChannels) { int newSize = totalChannels * 2; // Make a larger array SelectionKeyImpl temp[] = new SelectionKeyImpl[newSize]; System.arraycopy(channelArray, 1, temp, 1, totalChannels - 1); channelArray = temp; pollWrapper.grow(newSize); } if (totalChannels % MAX_SELECTABLE_FDS == 0) { // more threads needed pollWrapper.addWakeupSocket(wakeupSourceFd, totalChannels); totalChannels++; threadsCount++; } } // Initial capacity of the poll array privatefinalint INIT_CAP = 8; // Maximum number of sockets for select(). // Should be INIT_CAP times a power of 2 privatestaticfinalint MAX_SELECTABLE_FDS = 1024;
// The list of SelectableChannels serviced by this Selector. Every mod // MAX_SELECTABLE_FDS entry is bogus, to align this array with the poll // array, where the corresponding entry is occupied by the wakeupSocket private SelectionKeyImpl[] channelArray = new SelectionKeyImpl[INIT_CAP]; // The number of valid entries in poll array, including entries occupied // by wakeup socket handle. privateint totalChannels = 1;
//sun.nio.ch.PollArrayWrapper#grow // Grows the pollfd array to new size voidgrow(int newSize){ PollArrayWrapper temp = new PollArrayWrapper(newSize); for (int i = 0; i < size; i++) replaceEntry(this, i, temp, i); pollArray.free(); pollArray = temp.pollArray; this.size = temp.size; pollArrayAddress = pollArray.address(); }
// Maps file descriptors to their indices in pollArray privatestaticfinalclassFdMapextendsHashMap<Integer, MapEntry> { staticfinallong serialVersionUID = 0L; private MapEntry get(int desc){ return get(Integer.valueOf(desc)); } private MapEntry put(SelectionKeyImpl ski){ return put(Integer.valueOf(ski.getFDVal()), new MapEntry(ski)); } private MapEntry remove(SelectionKeyImpl ski){ Integer fd = Integer.valueOf(ski.getFDVal()); MapEntry x = get(fd); if ((x != null) && (x.ski.channel() == ski.channel())) return remove(fd); returnnull; } }
// class for fdMap entries privatestaticfinalclassMapEntry{ final SelectionKeyImpl ski; long updateCount = 0; MapEntry(SelectionKeyImpl ski) { this.ski = ski; } } privatefinal FdMap fdMap = new FdMap();
/** * sun.nio.ch.SelectorImpl#processDeregisterQueue * Invoked by selection operations to process the cancelled-key set */ protectedfinalvoidprocessDeregisterQueue()throws IOException { assert Thread.holdsLock(this); assert Thread.holdsLock(publicSelectedKeys);
Set<SelectionKey> cks = cancelledKeys(); synchronized (cks) { if (!cks.isEmpty()) { Iterator<SelectionKey> i = cks.iterator(); while (i.hasNext()) { SelectionKeyImpl ski = (SelectionKeyImpl)i.next(); i.remove();
// remove the key from the selector implDereg(ski);
if (fdMap.remove(ski) != null) { int i = ski.getIndex(); assert (i >= 0);
if (i != totalChannels - 1) { // Copy end one over it SelectionKeyImpl endChannel = channelArray[totalChannels-1]; channelArray[i] = endChannel; endChannel.setIndex(i); pollWrapper.replaceEntry(pollWrapper, totalChannels-1, pollWrapper, i); } ski.setIndex(-1);
channelArray[totalChannels - 1] = null; totalChannels--; if (totalChannels != 1 && totalChannels % MAX_SELECTABLE_FDS == 1) { totalChannels--; threadsCount--; // The last thread has become redundant. } } }
//sun.nio.ch.WindowsSelectorImpl#adjustThreadsCount // After some channels registered/deregistered, the number of required // helper threads may have changed. Adjust this number. privatevoidadjustThreadsCount(){ if (threadsCount > threads.size()) { // More threads needed. Start more threads. for (int i = threads.size(); i < threadsCount; i++) { SelectThread newThread = new SelectThread(i); threads.add(newThread); newThread.setDaemon(true); newThread.start(); } } elseif (threadsCount < threads.size()) { // Some threads become redundant. Remove them from the threads List. for (int i = threads.size() - 1 ; i >= threadsCount; i--) threads.remove(i).makeZombie(); } }
//sun.nio.ch.WindowsSelectorImpl.SelectThread // Represents a helper thread used for select. privatefinalclassSelectThreadextendsThread{ privatefinalint index; // index of this thread final SubSelector subSelector; privatelong lastRun = 0; // last run number privatevolatileboolean zombie; // Creates a new thread privateSelectThread(int i){ super(null, null, "SelectorHelper", 0, false); this.index = i; this.subSelector = new SubSelector(i); //make sure we wait for next round of poll this.lastRun = startLock.runsCounter; } voidmakeZombie(){ zombie = true; } booleanisZombie(){ return zombie; } publicvoidrun(){ while (true) { // poll loop // wait for the start of poll. If this thread has become // redundant, then exit. if (startLock.waitForStart(this)) return; // call poll() try { subSelector.poll(index); } catch (IOException e) { // Save this exception and let other threads finish. finishLock.setException(e); } // notify main thread, that this thread has finished, and // wakeup others, if this thread is the first to finish. finishLock.threadFinished(); } } }
// sun.nio.ch.WindowsSelectorImpl.FinishLock#threadFinished // Each helper thread invokes this function on finishLock, when // the thread is done with poll(). privatesynchronizedvoidthreadFinished(){ if (threadsToFinish == threads.size()) { // finished poll() first // if finished first, wakeup others wakeup(); } threadsToFinish--; if (threadsToFinish == 0) // all helper threads finished poll(). notify(); // notify the main thread }
//sun.nio.ch.WindowsSelectorImpl#wakeup @Override public Selector wakeup(){ synchronized (interruptLock) { if (!interruptTriggered) { setWakeupSocket(); interruptTriggered = true; } } returnthis; } //sun.nio.ch.WindowsSelectorImpl#setWakeupSocket // Sets Windows wakeup socket to a signaled state. privatevoidsetWakeupSocket(){ setWakeupSocket0(wakeupSinkFd); } privatenativevoidsetWakeupSocket0(int wakeupSinkFd);
JNIEXPORT void JNICALL Java_sun_nio_ch_WindowsSelectorImpl_setWakeupSocket0(JNIEnv *env, jclass this, jint scoutFd) { /* Write one byte into the pipe */ constcharbyte = 1; send(scoutFd, &byte, 1, 0); }
//sun.nio.ch.WindowsSelectorImpl.SubSelector privatefinalclassSubSelector{ privatefinalint pollArrayIndex; // starting index in pollArray to poll // These arrays will hold result of native select(). // The first element of each array is the number of selected sockets. // Other elements are file descriptors of selected sockets. // 保存发生read的FD privatefinalint[] readFds = newint [MAX_SELECTABLE_FDS + 1]; // 保存发生write的FD privatefinalint[] writeFds = newint [MAX_SELECTABLE_FDS + 1]; //保存发生except的FD privatefinalint[] exceptFds = newint [MAX_SELECTABLE_FDS + 1];
privateSubSelector(){ this.pollArrayIndex = 0; // main thread }
/** * sun.nio.ch.WindowsSelectorImpl.SubSelector#processFDSet * updateCount is used to tell if a key has been counted as updated * in this select operation. * * me.updateCount <= updateCount */ privateintprocessFDSet(long updateCount, Consumer<SelectionKey> action, int[] fds, int rOps, boolean isExceptFds) { int numKeysUpdated = 0; for (int i = 1; i <= fds[0]; i++) { int desc = fds[i]; if (desc == wakeupSourceFd) { synchronized (interruptLock) { interruptTriggered = true; } continue; } MapEntry me = fdMap.get(desc); // If me is null, the key was deregistered in the previous // processDeregisterQueue. if (me == null) continue; SelectionKeyImpl sk = me.ski;
// The descriptor may be in the exceptfds set because there is // OOB data queued to the socket. If there is OOB data then it // is discarded and the key is not added to the selected set. if (isExceptFds && (sk.channel() instanceof SocketChannelImpl) && discardUrgentData(desc)) { continue; } //我们应该关注的 int updated = processReadyEvents(rOps, sk, action); if (updated > 0 && me.updateCount != updateCount) { me.updateCount = updateCount; numKeysUpdated++; } } return numKeysUpdated; }
//sun.nio.ch.ServerSocketChannelImpl#accept() @Override public SocketChannel accept()throws IOException { acceptLock.lock(); try { int n = 0; FileDescriptor newfd = new FileDescriptor(); InetSocketAddress[] isaa = new InetSocketAddress[1];
boolean blocking = isBlocking(); try { begin(blocking); do { n = accept(this.fd, newfd, isaa); } while (n == IOStatus.INTERRUPTED && isOpen()); } finally { end(blocking, n > 0); assert IOStatus.check(n); }
if (n < 1) returnnull; //针对接受连接的处理通道socketchannelimpl,默认为阻塞模式 // newly accepted socket is initially in blocking mode IOUtil.configureBlocking(newfd, true);
InetSocketAddress isa = isaa[0]; //构建SocketChannelImpl,这个具体在SocketChannelImpl再说 SocketChannel sc = new SocketChannelImpl(provider(), newfd, isa);
// check permitted to accept connections from the remote address SecurityManager sm = System.getSecurityManager(); if (sm != null) { try { //检查地址和port权限 sm.checkAccept(isa.getAddress().getHostAddress(), isa.getPort()); } catch (SecurityException x) { sc.close(); throw x; } } //返回socketchannelimpl return sc;
// only simple values supported by this method Class<?> type = name.type();
if (extendedOptions.isOptionSupported(name)) { extendedOptions.setOption(fd, name, value); return; } //非整形和布尔型,则抛出断言错误 if (type != Integer.class && type != Boolean.class) thrownew AssertionError("Should not reach here");
// special handling if (name == StandardSocketOptions.SO_RCVBUF || name == StandardSocketOptions.SO_SNDBUF) { //判断接受和发送缓冲区大小 int i = ((Integer)value).intValue(); if (i < 0) thrownew IllegalArgumentException("Invalid send/receive buffer size"); } //缓冲区有数据,延迟关闭socket的的时间 if (name == StandardSocketOptions.SO_LINGER) { int i = ((Integer)value).intValue(); if (i < 0) value = Integer.valueOf(-1); if (i > 65535) value = Integer.valueOf(65535); } //UDP单播 if (name == StandardSocketOptions.IP_TOS) { int i = ((Integer)value).intValue(); if (i < 0 || i > 255) thrownew IllegalArgumentException("Invalid IP_TOS value"); } //UDP多播 if (name == StandardSocketOptions.IP_MULTICAST_TTL) { int i = ((Integer)value).intValue(); if (i < 0 || i > 255) thrownew IllegalArgumentException("Invalid TTL/hop value"); }
// map option name to platform level/name OptionKey key = SocketOptionRegistry.findOption(name, family); if (key == null) thrownew AssertionError("Option not found");
int arg; //转换配置参数值 if (type == Integer.class) { arg = ((Integer)value).intValue(); } else { boolean b = ((Boolean)value).booleanValue(); arg = (b) ? 1 : 0; }
//sun.nio.ch.ServerSocketChannelImpl#getOption @Override @SuppressWarnings("unchecked") public <T> T getOption(SocketOption<T> name) throws IOException { Objects.requireNonNull(name); //非通道支持选项,则抛出UnsupportedOperationException if (!supportedOptions().contains(name)) thrownew UnsupportedOperationException("'" + name + "' not supported");
synchronized (stateLock) { ensureOpen(); if (name == StandardSocketOptions.SO_REUSEADDR && Net.useExclusiveBind()) { // SO_REUSEADDR emulated when using exclusive bind return (T)Boolean.valueOf(isReuseAddress); } //假如获取的不是上面的配置,则委托给Net来处理 // no options that require special handling return (T) Net.getSocketOption(fd, Net.UNSPEC, name); } } //sun.nio.ch.Net#getSocketOption static Object getSocketOption(FileDescriptor fd, ProtocolFamily family, SocketOption<?> name) throws IOException { Class<?> type = name.type();
if (extendedOptions.isOptionSupported(name)) { return extendedOptions.getOption(fd, name); } //只支持整形和布尔型,否则抛出断言错误 // only simple values supported by this method if (type != Integer.class && type != Boolean.class) thrownew AssertionError("Should not reach here");
// map option name to platform level/name OptionKey key = SocketOptionRegistry.findOption(name, family); if (key == null) thrownew AssertionError("Option not found");
boolean mayNeedConversion = (family == UNSPEC); //获取文件描述的选项配置 int value = getIntOption0(fd, mayNeedConversion, key.level(), key.name());
//java.net.ServerSocket publicServerSocket(int port, int backlog, InetAddress bindAddr)throws IOException { setImpl(); if (port < 0 || port > 0xFFFF) thrownew IllegalArgumentException( "Port value out of range: " + port); if (backlog < 1) backlog = 50; try { bind(new InetSocketAddress(bindAddr, port), backlog); } catch(SecurityException e) { close(); throw e; } catch(IOException e) { close(); throw e; } } //java.net.ServerSocket#setImpl privatevoidsetImpl(){ if (factory != null) { impl = factory.createSocketImpl(); checkOldImpl(); } else { // No need to do a checkOldImpl() here, we know it's an up to date // SocketImpl! impl = new SocksSocketImpl(); } if (impl != null) impl.setServerSocket(this); }
//java.net.AbstractPlainSocketImpl#create protectedsynchronizedvoidcreate(boolean stream)throws IOException { this.stream = stream; if (!stream) { ResourceManager.beforeUdpCreate(); // only create the fd after we know we will be able to create the socket fd = new FileDescriptor(); try { socketCreate(false); SocketCleanable.register(fd); } catch (IOException ioe) { ResourceManager.afterUdpClose(); fd = null; throw ioe; } } else { fd = new FileDescriptor(); socketCreate(true); SocketCleanable.register(fd); } if (socket != null) socket.setCreated(); if (serverSocket != null) serverSocket.setCreated(); }
// clone keys to avoid calling cancel when holding keyLock SelectionKey[] copyOfKeys = null; synchronized (keyLock) { if (keys != null) { copyOfKeys = keys.clone(); } }
if (copyOfKeys != null) { for (SelectionKey k : copyOfKeys) { if (k != null) { k.cancel(); // invalidate and adds key to cancelledKey set } } } } //sun.nio.ch.ServerSocketChannelImpl#implCloseSelectableChannel @Override protectedvoidimplCloseSelectableChannel()throws IOException { assert !isOpen();
boolean interrupted = false; boolean blocking;
// set state to ST_CLOSING synchronized (stateLock) { assert state < ST_CLOSING; state = ST_CLOSING; blocking = isBlocking(); }
// wait for any outstanding accept to complete if (blocking) { synchronized (stateLock) { assert state == ST_CLOSING; long th = thread; if (th != 0) { //本地线程不为null,则本地Socket预先关闭 //并通知线程通知关闭 nd.preClose(fd); NativeThread.signal(th);
// wait for accept operation to end while (thread != 0) { try { stateLock.wait(); } catch (InterruptedException e) { interrupted = true; } } } } } else { // non-blocking mode: wait for accept to complete acceptLock.lock(); acceptLock.unlock(); }
// set state to ST_KILLPENDING synchronized (stateLock) { assert state == ST_CLOSING; state = ST_KILLPENDING; }
// close socket if not registered with Selector //如果未在Selector上注册,直接kill掉 //即关闭文件描述 if (!isRegistered()) kill();
// restore interrupt status //印证了我们上一篇中在异步打断中若是通过线程的中断方法中断线程的话 //最后要设定该线程状态是interrupt if (interrupted) Thread.currentThread().interrupt(); }
@Override publicvoidkill()throws IOException { synchronized (stateLock) { if (state == ST_KILLPENDING) { state = ST_KILLED; nd.close(fd); } } }
/** * Used for standard input, output, and error only. * For Windows the corresponding handle is initialized. * For Unix the append mode is cached. * 仅用于标准输入,输出和错误。 * 对于Windows,初始化相应的句柄。 * 对于Unix,缓存附加模式。 * @param fd the raw fd number (0, 1, 2) */ privateFileDescriptor(int fd){ this.fd = fd; this.handle = getHandle(fd); this.append = getAppend(fd); } ... }
publicstaticfinal FileDescriptor in = new FileDescriptor(0); publicstaticfinal FileDescriptor out = new FileDescriptor(1); publicstaticfinal FileDescriptor err = new FileDescriptor(2);
/* Disable IPV6_V6ONLY to ensure dual-socket support */ if (domain == AF_INET6) { int arg = 0; //arg=1设置ipv6的socket只接收ipv6地址的报文,arg=0表示也可接受ipv4的请求 if (setsockopt(fd, IPPROTO_IPV6, IPV6_V6ONLY, (char*)&arg, sizeof(int)) < 0) { JNU_ThrowByNameWithLastError(env, JNU_JAVANETPKG "SocketException", "Unable to set IPV6_V6ONLY"); close(fd); return -1; } }
//SO_REUSEADDR有四种用途: //1.当有一个有相同本地地址和端口的socket1处于TIME_WAIT状态时,而你启动的程序的socket2要占用该地址和端口,你的程序就要用到该选项。 //2.SO_REUSEADDR允许同一port上启动同一服务器的多个实例(多个进程)。但每个实例绑定的IP地址是不能相同的。 //3.SO_REUSEADDR允许单个进程绑定相同的端口到多个socket上,但每个socket绑定的ip地址不同。 //4.SO_REUSEADDR允许完全相同的地址和端口的重复绑定。但这只用于UDP的多播,不用于TCP; if (reuse) { int arg = 1; if (setsockopt(fd, SOL_SOCKET, SO_REUSEADDR, (char*)&arg, sizeof(arg)) < 0) { JNU_ThrowByNameWithLastError(env, JNU_JAVANETPKG "SocketException", "Unable to set SO_REUSEADDR"); close(fd); return -1; } }
#if defined(__linux__) if (type == SOCK_DGRAM) { int arg = 0; int level = (domain == AF_INET6) ? IPPROTO_IPV6 : IPPROTO_IP; if ((setsockopt(fd, level, IP_MULTICAST_ALL, (char*)&arg, sizeof(arg)) < 0) && (errno != ENOPROTOOPT)) { JNU_ThrowByNameWithLastError(env, JNU_JAVANETPKG "SocketException", "Unable to set IP_MULTICAST_ALL"); close(fd); return -1; } }
//IPV6_MULTICAST_HOPS用于控制多播的范围, // 1表示只在本地网络转发, //更多介绍请参考(http://www.ctt.sbras.ru/cgi-bin/www/unix_help/unix-man?ip6+4); /* By default, Linux uses the route default */ if (domain == AF_INET6 && type == SOCK_DGRAM) { int arg = 1; if (setsockopt(fd, IPPROTO_IPV6, IPV6_MULTICAST_HOPS, &arg, sizeof(arg)) < 0) { JNU_ThrowByNameWithLastError(env, JNU_JAVANETPKG "SocketException", "Unable to set IPV6_MULTICAST_HOPS"); close(fd); return -1; } } #endif return fd; }
Linux 3.9之后加入了SO_REUSEPORT配置,这个配置很强大,多个socket(不管是处于监听还是非监听,不管是TCP还是UDP)只要在绑定之前设置了SO_REUSEPORT属性,那么就可以绑定到完全相同的地址和端口。 为了阻止”port 劫持”(Port hijacking)有一个特别的限制:所有希望共享源地址和端口的socket都必须拥有相同的有效用户id(effective user ID)。这样一个用户就不能从另一个用户那里”偷取”端口。另外,内核在处理SO_REUSEPORT socket的时候使用了其它系统上没有用到的”特殊技巧”:
publicvoidconnect(SocketAddress remote, int timeout)throws IOException { if (remote == null) thrownew IllegalArgumentException("connect: The address can't be null"); if (timeout < 0) thrownew IllegalArgumentException("connect: timeout can't be negative");
synchronized (sc.blockingLock()) { if (!sc.isBlocking()) thrownew IllegalBlockingModeException();
/** * Tells whether or not this channel is open. * * @return {@code true} if, and only if, this channel is open */ publicbooleanisOpen();
/** * Closes this channel. * * <p> After a channel is closed, any further attempt to invoke I/O * operations upon it will cause a {@link ClosedChannelException} to be * thrown. * * <p> If this channel is already closed then invoking this method has no * effect. * * <p> This method may be invoked at any time. If some other thread has * already invoked it, however, then another invocation will block until * the first invocation is complete, after which it will return without * effect. </p> * * @throws IOException If an I/O error occurs */ publicvoidclose()throws IOException;
/** * Closes this channel. * * <p> Any thread currently blocked in an I/O operation upon this channel * will receive an {@link AsynchronousCloseException}. * * <p> This method otherwise behaves exactly as specified by the {@link * Channel#close Channel} interface. </p> * * @throws IOException If an I/O error occurs */ publicvoidclose()throws IOException;
//java.nio.channels.spi.AbstractSelectionKey#cancel /** * Cancels this key. * * <p> If this key has not yet been cancelled then it is added to its * selector's cancelled-key set while synchronized on that set. </p> */ publicfinalvoidcancel(){ // Synchronizing "this" to prevent this key from getting canceled // multiple times by different threads, which might cause race // condition between selector's select() and channel's close(). synchronized (this) { if (valid) { valid = false; //还是调用Selector的cancel方法 ((AbstractSelector)selector()).cancel(this); } } }
/** * sun.nio.ch.SelectorImpl#processDeregisterQueue * Invoked by selection operations to process the cancelled-key set */ protectedfinalvoidprocessDeregisterQueue()throws IOException { assert Thread.holdsLock(this); assert Thread.holdsLock(publicSelectedKeys);
Set<SelectionKey> cks = cancelledKeys(); synchronized (cks) { if (!cks.isEmpty()) { Iterator<SelectionKey> i = cks.iterator(); while (i.hasNext()) { SelectionKeyImpl ski = (SelectionKeyImpl)i.next(); i.remove();
// remove the key from the selector implDereg(ski);
//java.nio.channels.spi.AbstractInterruptibleChannel#close /** * Closes this channel. * * <p> If the channel has already been closed then this method returns * immediately. Otherwise it marks the channel as closed and then invokes * the {@link #implCloseChannel implCloseChannel} method in order to * complete the close operation. </p> * * @throws IOException * If an I/O error occurs */ publicfinalvoidclose()throws IOException { synchronized (closeLock) { if (closed) return; closed = true; implCloseChannel(); } } //java.nio.channels.spi.AbstractSelectableChannel#implCloseChannel protectedfinalvoidimplCloseChannel()throws IOException { implCloseSelectableChannel();
// clone keys to avoid calling cancel when holding keyLock SelectionKey[] copyOfKeys = null; synchronized (keyLock) { if (keys != null) { copyOfKeys = keys.clone(); } }
if (copyOfKeys != null) { for (SelectionKey k : copyOfKeys) { if (k != null) { k.cancel(); // invalidate and adds key to cancelledKey set } } } }
public String stringNowTime(){ SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); return format.format(new Date()); }
publicstaticvoidmain(String[] args){ BIOClient client = new BIOClient(); client.initBIOClient("127.0.0.1", 8888); }
}
通过上面的例子,我们可以知道,无论是服务端还是客户端,我们关注的几个操作有基于服务端的serverSocket = new ServerSocket(port)serverSocket.accept(),基于客户端的Socket socket = new Socket(host, port); 以及两者都有的读取与写入Socket数据的方式,即通过流来进行读写,这个读写不免通过一个中间字节数组buffer来进行。
/** * The factory for all server sockets. */ privatestatic SocketImplFactory factory = null; privatevoidsetImpl(){ if (factory != null) { impl = factory.createSocketImpl(); checkOldImpl(); } else { // No need to do a checkOldImpl() here, we know it's an up to date // SocketImpl! impl = new SocksSocketImpl(); } if (impl != null) impl.setServerSocket(this); } /** * Get the {@code SocketImpl} attached to this socket, creating * it if necessary. * * @return the {@code SocketImpl} attached to that ServerSocket. * @throws SocketException if creation fails. * @since 1.4 */ SocketImpl getImpl()throws SocketException { if (!created) createImpl(); return impl; } /** * Creates the socket implementation. * * @throws IOException if creation fails * @since 1.4 */ voidcreateImpl()throws SocketException { if (impl == null) setImpl(); try { impl.create(true); created = true; } catch (IOException e) { thrownew SocketException(e.getMessage()); } }
//java.net.AbstractPlainSocketImpl#bind /** * Binds the socket to the specified address of the specified local port. * @param address the address * @param lport the port */ protectedsynchronizedvoidbind(InetAddress address, int lport) throws IOException { synchronized (fdLock) { if (!closePending && (socket == null || !socket.isBound())) { NetHooks.beforeTcpBind(fd, address, lport); } } socketBind(address, lport); if (socket != null) socket.setBound(); if (serverSocket != null) serverSocket.setBound(); }
//java.net.PlainSocketImpl#socketBind @Override voidsocketBind(InetAddress address, int port)throws IOException { int nativefd = checkAndReturnNativeFD();
if (address == null) thrownew NullPointerException("inet address argument is null.");
if (preferIPv4Stack && !(address instanceof Inet4Address)) thrownew SocketException("Protocol family not supported");
public Socket accept()throws IOException { if (isClosed()) thrownew SocketException("Socket is closed"); if (!isBound()) thrownew SocketException("Socket is not bound yet"); Socket s = new Socket((SocketImpl) null); implAccept(s); return s; }
/** * Subclasses of ServerSocket use this method to override accept() * to return their own subclass of socket. So a FooServerSocket * will typically hand this method an <i>empty</i> FooSocket. On * return from implAccept the FooSocket will be connected to a client. * * @param s the Socket * @throws java.nio.channels.IllegalBlockingModeException * if this socket has an associated channel, * and the channel is in non-blocking mode * @throws IOException if an I/O error occurs when waiting * for a connection. * @since 1.1 * @revised 1.4 * @spec JSR-51 */ protectedfinalvoidimplAccept(Socket s)throws IOException { SocketImpl si = null; try { if (s.impl == null) s.setImpl(); else { s.impl.reset(); } si = s.impl; s.impl = null; si.address = new InetAddress(); si.fd = new FileDescriptor(); getImpl().accept(si); // <1> SocketCleanable.register(si.fd); // raw fd has been set
/** * Enable/disable {@link SocketOptions#SO_TIMEOUT SO_TIMEOUT} with the * specified timeout, in milliseconds. With this option set to a non-zero * timeout, a call to accept() for this ServerSocket * will block for only this amount of time. If the timeout expires, * a <B>java.net.SocketTimeoutException</B> is raised, though the * ServerSocket is still valid. The option <B>must</B> be enabled * prior to entering the blocking operation to have effect. The * timeout must be {@code > 0}. * A timeout of zero is interpreted as an infinite timeout. * @param timeout the specified timeout, in milliseconds * @exception SocketException if there is an error in * the underlying protocol, such as a TCP error. * @since 1.1 * @see #getSoTimeout() */ publicsynchronizedvoidsetSoTimeout(int timeout)throws SocketException { if (isClosed()) thrownew SocketException("Socket is closed"); getImpl().setOption(SocketOptions.SO_TIMEOUT, timeout); }
2019-01-02 17:28:43:362: serverSocket started now time is: 2019-01-02 17:28:44:363 now time is: 2019-01-02 17:28:45:363 now time is: 2019-01-02 17:28:46:363 now time is: 2019-01-02 17:28:47:363 now time is: 2019-01-02 17:28:48:363 now time is: 2019-01-02 17:28:49:363 now time is: 2019-01-02 17:28:50:363 now time is: 2019-01-02 17:28:51:364 now time is: 2019-01-02 17:28:52:365 now time is: 2019-01-02 17:28:53:365 now time is: 2019-01-02 17:28:54:365 now time is: 2019-01-02 17:28:55:365 now time is: 2019-01-02 17:28:56:365 // <1> 2019-01-02 17:28:56:911: id为1308927845的Clientsocket connected now time is: 2019-01-02 17:28:57:913 // <2> now time is: 2019-01-02 17:28:58:913
可以看到,我们刚开始并没有客户端接入的时候,是会执行System.out.println("now time is: " + stringNowTime());的输出,还有一点需要注意的就是,仔细看看上面的输出结果的标记<1>与<2>,你会发现<2>处时间值不是17:28:57:365,原因就在于如果accept正常返回值的话,是不会执行catch语句部分的。
publicintread(byte b[], int off, int length)throws IOException { return read(b, off, length, impl.getTimeout()); }
intread(byte b[], int off, int length, int timeout)throws IOException { int n;
// EOF already encountered if (eof) { return -1; }
// connection reset if (impl.isConnectionReset()) { thrownew SocketException("Connection reset"); }
// bounds check if (length <= 0 || off < 0 || length > b.length - off) { if (length == 0) { return0; } thrownew ArrayIndexOutOfBoundsException("length == " + length + " off == " + off + " buffer length == " + b.length); }
// acquire file descriptor and do the read FileDescriptor fd = impl.acquireFD(); try { n = socketRead(fd, b, off, length, timeout); if (n > 0) { return n; } } catch (ConnectionResetException rstExc) { impl.setConnectionReset(); } finally { impl.releaseFD(); }
/* * If we get here we are at EOF, the socket has been closed, * or the connection has been reset. */ if (impl.isClosedOrPending()) { thrownew SocketException("Socket closed"); } if (impl.isConnectionReset()) { thrownew SocketException("Connection reset"); } eof = true; return -1; } privateintsocketRead(FileDescriptor fd, byte b[], int off, int len, int timeout) throws IOException { return socketRead0(fd, b, off, len, timeout); }
2019-01-02 17:59:03:713: serverSocket started now time is: 2019-01-02 17:59:04:714 now time is: 2019-01-02 17:59:05:714 now time is: 2019-01-02 17:59:06:714 2019-01-02 17:59:06:932: id为1810132623的Clientsocket connected now time is: 2019-01-02 17:59:07:934 Not read data: 2019-01-02 17:59:07:935 now time is: 2019-01-02 17:59:08:934 Not read data: 2019-01-02 17:59:08:935 now time is: 2019-01-02 17:59:09:935 Not read data: 2019-01-02 17:59:09:936 收到id为1810132623 2019-01-02 17:59:09: 第0条消息: ccc // <1> now time is: 2019-01-02 17:59:10:935 Not read data: 2019-01-02 17:59:10:981 // <2> 收到id为1810132623 2019-01-02 17:59:11: 第1条消息: bbb now time is: 2019-01-02 17:59:11:935 Not read data: 2019-01-02 17:59:12:470 now time is: 2019-01-02 17:59:12:935 id为1810132623的Clientsocket 2019-01-02 17:59:13:191读取结束 now time is: 2019-01-02 17:59:13:935 id为1810132623的Clientsocket 2019-01-02 17:59:14:192读取结束
// Register shutdown hook if (useShutdownHook) { if (shutdownHook == null) { shutdownHook = new CatalinaShutdownHook(); } Runtime.getRuntime().addShutdownHook(shutdownHook);
// If JULI is being used, disable JULI's shutdown hook since // shutdown hooks run in parallel and log messages may be lost // if JULI's hook completes before the CatalinaShutdownHook() LogManager logManager = LogManager.getLogManager(); if (logManager instanceof ClassLoaderLogManager) { ((ClassLoaderLogManager) logManager).setUseShutdownHook( false); } }
try { setStateInternal(LifecycleState.STARTING_PREP, null, false); startInternal(); if (state.equals(LifecycleState.FAILED)) { // This is a 'controlled' failure. The component put itself into the // FAILED state so call stop() to complete the clean-up. stop(); } elseif (!state.equals(LifecycleState.STARTING)) { // Shouldn't be necessary but acts as a check that sub-classes are // doing what they are supposed to. invalidTransition(Lifecycle.AFTER_START_EVENT); } else { setStateInternal(LifecycleState.STARTED, null, false); } } catch (Throwable t) { // This is an 'uncontrolled' failure so put the component into the // FAILED state and throw an exception. handleSubClassException(t, "lifecycleBase.startFail", toString()); } }
if (protocolHandler == null) { thrownew LifecycleException( sm.getString("coyoteConnector.protocolHandlerInstantiationFailed")); }
// Initialize adapter adapter = new CoyoteAdapter(this); protocolHandler.setAdapter(adapter); if (service != null) { protocolHandler.setUtilityExecutor(service.getServer().getUtilityExecutor()); }
// Make sure parseBodyMethodsSet has a default if (null == parseBodyMethodsSet) { setParseBodyMethods(getParseBodyMethods()); }
if (protocolHandler.isAprRequired() && !AprLifecycleListener.isAprAvailable()) { thrownew LifecycleException(sm.getString("coyoteConnector.protocolHandlerNoApr", getProtocolHandlerClassName())); } if (AprLifecycleListener.isAprAvailable() && AprLifecycleListener.getUseOpenSSL() && protocolHandler instanceof AbstractHttp11JsseProtocol) { AbstractHttp11JsseProtocol<?> jsseProtocolHandler = (AbstractHttp11JsseProtocol<?>) protocolHandler; if (jsseProtocolHandler.isSSLEnabled() && jsseProtocolHandler.getSslImplementationName() == null) { // OpenSSL is compatible with the JSSE configuration, so use it if APR is available jsseProtocolHandler.setSslImplementationName(OpenSSLImplementation.class.getName()); } }
// Initialize thread count defaults for acceptor, poller if (acceptorThreadCount == 0) { // FIXME: Doesn't seem to work that well with multiple accept threads acceptorThreadCount = 1; } if (pollerThreadCount <= 0) { //minimum one poller thread pollerThreadCount = 1; } setStopLatch(new CountDownLatch(pollerThreadCount));
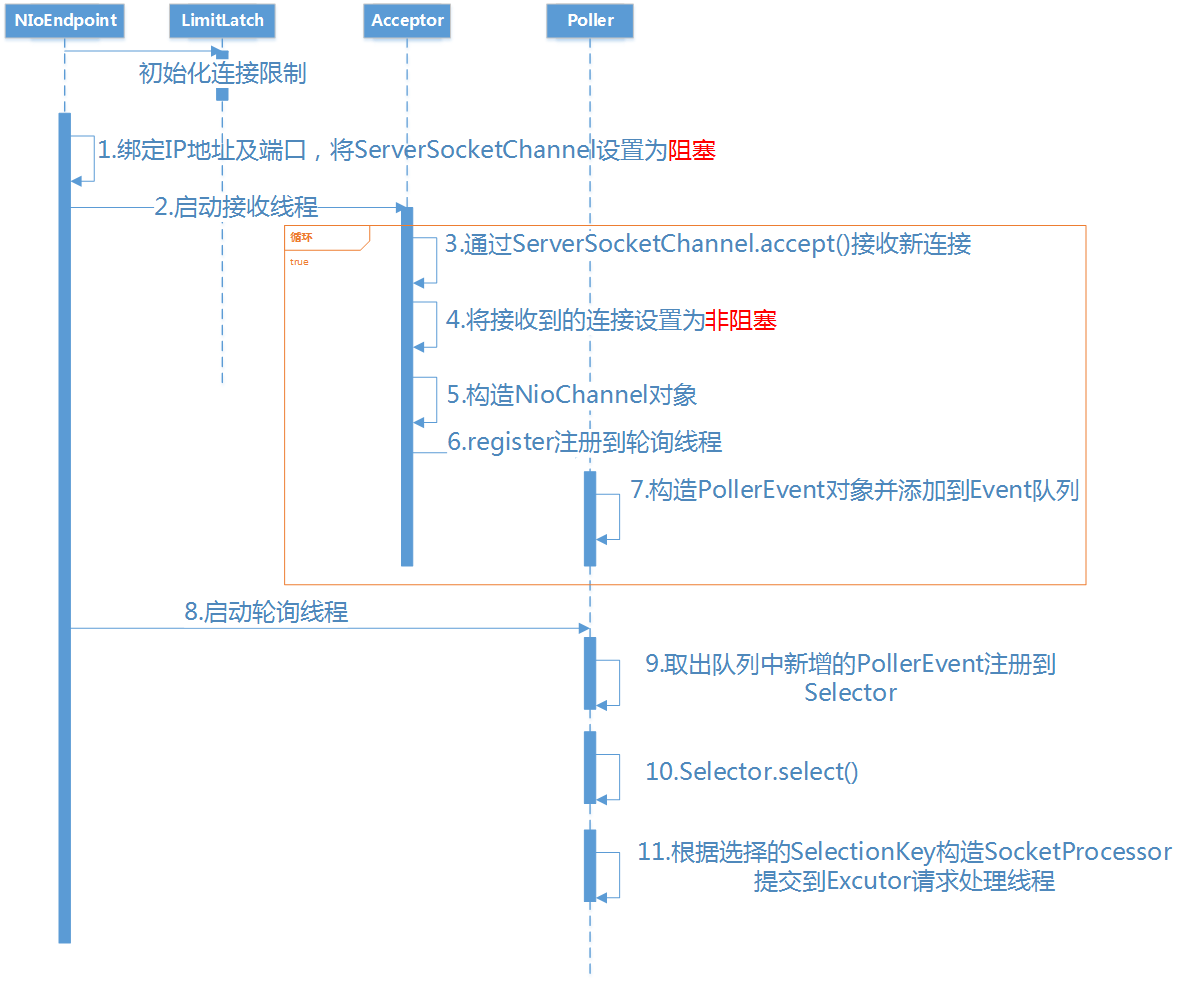
// Separated out to make it easier for folks that extend NioEndpoint to // implement custom [server]sockets protectedvoidinitServerSocket()throws Exception { if (!getUseInheritedChannel()) { serverSock = ServerSocketChannel.open(); socketProperties.setProperties(serverSock.socket()); InetSocketAddress addr = new InetSocketAddress(getAddress(), getPortWithOffset()); serverSock.socket().bind(addr,getAcceptCount()); } else { // Retrieve the channel provided by the OS Channel ic = System.inheritedChannel(); if (ic instanceof ServerSocketChannel) { serverSock = (ServerSocketChannel) ic; } if (serverSock == null) { thrownew IllegalArgumentException(sm.getString("endpoint.init.bind.inherited")); } } serverSock.configureBlocking(true); //mimic APR behavior }
processorCache = new SynchronizedStack<>(SynchronizedStack.DEFAULT_SIZE, socketProperties.getProcessorCache()); eventCache = new SynchronizedStack<>(SynchronizedStack.DEFAULT_SIZE, socketProperties.getEventCache()); nioChannels = new SynchronizedStack<>(SynchronizedStack.DEFAULT_SIZE, socketProperties.getBufferPool());
<attributename="acceptorThreadCount"required="false"> <p>The number of threads to be used to accept connections. Increase this value on a multi CPU machine, although you would never really need more than <code>2</code>. Also, with a lot of non keep alive connections, you might want to increase this value as well. Default value is <code>1</code>.</p> </attribute>
<attributename="pollerThreadCount"required="false"> <p>(int)The number of threads to be used to run for the polling events. Default value is <code>1</code> per processor but not more than 2.<br/> When accepting a socket, the operating system holds a global lock. So the benefit of going above 2 threads diminishes rapidly. Having more than one thread is for system that need to accept connections very rapidly. However usually just increasing <code>acceptCount</code> will solve that problem. Increasing this value may also be beneficial when a large amount of send file operations are going on. </p> </attribute>
final String getThreadName(){ return threadName; }
@Override publicvoidrun(){
int errorDelay = 0;
// Loop until we receive a shutdown command while (endpoint.isRunning()) {
// Loop if endpoint is paused while (endpoint.isPaused() && endpoint.isRunning()) { state = AcceptorState.PAUSED; try { Thread.sleep(50); } catch (InterruptedException e) { // Ignore } }
if (!endpoint.isRunning()) { break; } state = AcceptorState.RUNNING;
try { //if we have reached max connections, wait endpoint.countUpOrAwaitConnection();
// Endpoint might have been paused while waiting for latch // If that is the case, don't accept new connections if (endpoint.isPaused()) { continue; }
U socket = null; try { // Accept the next incoming connection from the server // socket // 创建一个socketChannel,接收下一个从服务器进来的连接 socket = endpoint.serverSocketAccept(); } catch (Exception ioe) { // We didn't get a socket endpoint.countDownConnection(); if (endpoint.isRunning()) { // Introduce delay if necessary errorDelay = handleExceptionWithDelay(errorDelay); // re-throw throw ioe; } else { break; } } // Successful accept, reset the error delay errorDelay = 0;
// Configure the socket // 如果EndPoint处于running状态并且没有没暂停 if (endpoint.isRunning() && !endpoint.isPaused()) { // setSocketOptions() will hand the socket off to // an appropriate processor if successful if (!endpoint.setSocketOptions(socket)) { endpoint.closeSocket(socket); } } else { endpoint.destroySocket(socket); } } catch (Throwable t) { ExceptionUtils.handleThrowable(t); String msg = sm.getString("endpoint.accept.fail"); // APR specific. // Could push this down but not sure it is worth the trouble. if (t instanceof Error) { Error e = (Error) t; if (e.getError() == 233) { // Not an error on HP-UX so log as a warning // so it can be filtered out on that platform // See bug 50273 log.warn(msg, t); } else { log.error(msg, t); } } else { log.error(msg, t); } } } state = AcceptorState.ENDED; }
/** * org.apache.tomcat.util.net.NioEndpoint.java * Process the specified connection. * 处理指定的连接 * @param socket The socket channel * @return <code>true</code> if the socket was correctly configured * and processing may continue, <code>false</code> if the socket needs to be * close immediately * 如果socket配置正确,并且可能会继续处理,返回true * 如果socket需要立即关闭,则返回false */ @Override protectedbooleansetSocketOptions(SocketChannel socket){ // Process the connection try { //disable blocking, APR style, we are gonna be polling it socket.configureBlocking(false); Socket sock = socket.socket(); socketProperties.setProperties(sock); //从缓存中拿一个nioChannel 若没有,则创建一个。将socket传进去 NioChannel channel = nioChannels.pop(); if (channel == null) { SocketBufferHandler bufhandler = new SocketBufferHandler( socketProperties.getAppReadBufSize(), socketProperties.getAppWriteBufSize(), socketProperties.getDirectBuffer()); if (isSSLEnabled()) { channel = new SecureNioChannel(socket, bufhandler, selectorPool, this); } else { channel = new NioChannel(socket, bufhandler); } } else { channel.setIOChannel(socket); channel.reset(); } //从pollers数组中获取一个Poller对象,注册这个nioChannel getPoller0().register(channel); } catch (Throwable t) { ExceptionUtils.handleThrowable(t); try { log.error(sm.getString("endpoint.socketOptionsError"), t); } catch (Throwable tt) { ExceptionUtils.handleThrowable(tt); } // Tell to close the socket returnfalse; } returntrue; }
/** * Return an available poller in true round robin fashion. * * @return The next poller in sequence */ public Poller getPoller0(){ int idx = Math.abs(pollerRotater.incrementAndGet()) % pollers.length; return pollers[idx]; }
/** * Registers a newly created socket with the poller. * * @param socket The newly created socket */ publicvoidregister(final NioChannel socket){ socket.setPoller(this); NioSocketWrapper ka = new NioSocketWrapper(socket, NioEndpoint.this); socket.setSocketWrapper(ka); ka.setPoller(this); ka.setReadTimeout(getConnectionTimeout()); ka.setWriteTimeout(getConnectionTimeout()); ka.setKeepAliveLeft(NioEndpoint.this.getMaxKeepAliveRequests()); ka.setSecure(isSSLEnabled()); //从缓存中取出一个PollerEvent对象,若没有则创建一个。将socket和NioSocketWrapper设置进去 PollerEvent r = eventCache.pop(); ka.interestOps(SelectionKey.OP_READ);//this is what OP_REGISTER turns into. if ( r==null) r = new PollerEvent(socket,ka,OP_REGISTER); else r.reset(socket,ka,OP_REGISTER); //添到到该Poller的事件列表 addEvent(r); }
/** * The background thread that adds sockets to the Poller, checks the * poller for triggered events and hands the associated socket off to an * appropriate processor as events occur. */ @Override publicvoidrun(){ // Loop until destroy() is called // 循环直到 destroy() 被调用 while (true) {
boolean hasEvents = false;
try { if (!close) { //遍历events,将每个事件中的Channel的interestOps注册到Selector中 hasEvents = events(); if (wakeupCounter.getAndSet(-1) > 0) { //if we are here, means we have other stuff to do //do a non blocking select //如果走到了这里,代表已经有就绪的IO Channel //调用非阻塞的select方法,直接返回就绪Channel的数量 keyCount = selector.selectNow(); } else { //阻塞等待操作系统返回 数据已经就绪的Channel,然后被唤醒 keyCount = selector.select(selectorTimeout); } wakeupCounter.set(0); } if (close) { events(); timeout(0, false); try { selector.close(); } catch (IOException ioe) { log.error(sm.getString("endpoint.nio.selectorCloseFail"), ioe); } break; } } catch (Throwable x) { ExceptionUtils.handleThrowable(x); log.error(sm.getString("endpoint.nio.selectorLoopError"), x); continue; } //either we timed out or we woke up, process events first //如果上面select方法超时,或者被唤醒,先将events队列中的Channel注册到Selector上。 if ( keyCount == 0 ) hasEvents = (hasEvents | events());
Iterator<SelectionKey> iterator = keyCount > 0 ? selector.selectedKeys().iterator() : null; // Walk through the collection of ready keys and dispatch // any active event. // 遍历已就绪的Channel,并调用processKey来处理该Socket的IO。 while (iterator != null && iterator.hasNext()) { SelectionKey sk = iterator.next(); NioSocketWrapper attachment = (NioSocketWrapper)sk.attachment(); // Attachment may be null if another thread has called // cancelledKey() // 如果其它线程已调用,则Attachment可能为空 if (attachment == null) { iterator.remove(); } else { iterator.remove(); //创建一个SocketProcessor,放入Tomcat线程池去执行 processKey(sk, attachment); } }//while
/** * Processes events in the event queue of the Poller. * * @return <code>true</code> if some events were processed, * <code>false</code> if queue was empty */ publicbooleanevents(){ boolean result = false;
PollerEvent pe = null; for (int i = 0, size = events.size(); i < size && (pe = events.poll()) != null; i++ ) { result = true; try { //把SocketChannel的interestOps注册到Selector中 pe.run(); pe.reset(); if (running && !paused) { eventCache.push(pe); } } catch ( Throwable x ) { log.error(sm.getString("endpoint.nio.pollerEventError"), x); } }
@Override publicvoidrun(){ //Acceptor调用Poller.register()方法时,创建的PollerEvent的interestOps为OP_REGISTER,因此走这个分支 if (interestOps == OP_REGISTER) { try { socket.getIOChannel().register( socket.getPoller().getSelector(), SelectionKey.OP_READ, socketWrapper); } catch (Exception x) { log.error(sm.getString("endpoint.nio.registerFail"), x); } } else { final SelectionKey key = socket.getIOChannel().keyFor(socket.getPoller().getSelector()); try { if (key == null) { // The key was cancelled (e.g. due to socket closure) // and removed from the selector while it was being // processed. Count down the connections at this point // since it won't have been counted down when the socket // closed. socket.socketWrapper.getEndpoint().countDownConnection(); ((NioSocketWrapper) socket.socketWrapper).closed = true; } else { final NioSocketWrapper socketWrapper = (NioSocketWrapper) key.attachment(); if (socketWrapper != null) { //we are registering the key to start with, reset the fairness counter. int ops = key.interestOps() | interestOps; socketWrapper.interestOps(ops); key.interestOps(ops); } else { socket.getPoller().cancelledKey(key); } } } catch (CancelledKeyException ckx) { try { socket.getPoller().cancelledKey(key); } catch (Exception ignore) {} } } }
/** * Process the given SocketWrapper with the given status. Used to trigger * processing as if the Poller (for those endpoints that have one) * selected the socket. * * @param socketWrapper The socket wrapper to process * @param event The socket event to be processed * @param dispatch Should the processing be performed on a new * container thread * * @return if processing was triggered successfully */ publicbooleanprocessSocket(SocketWrapperBase<S> socketWrapper, SocketEvent event, boolean dispatch){ try { if (socketWrapper == null) { returnfalse; } SocketProcessorBase<S> sc = processorCache.pop(); if (sc == null) { sc = createSocketProcessor(socketWrapper, event); } else { sc.reset(socketWrapper, event); } Executor executor = getExecutor(); if (dispatch && executor != null) { executor.execute(sc); } else { sc.run(); } } catch (RejectedExecutionException ree) { getLog().warn(sm.getString("endpoint.executor.fail", socketWrapper) , ree); returnfalse; } catch (Throwable t) { ExceptionUtils.handleThrowable(t); // This means we got an OOM or similar creating a thread, or that // the pool and its queue are full getLog().error(sm.getString("endpoint.process.fail"), t); returnfalse; } returntrue; }
// Separated out to make it easier for folks that extend NioEndpoint to // implement custom [server]sockets protectedvoidinitServerSocket()throws Exception { if (!getUseInheritedChannel()) { serverSock = ServerSocketChannel.open(); socketProperties.setProperties(serverSock.socket()); InetSocketAddress addr = new InetSocketAddress(getAddress(), getPortWithOffset()); serverSock.socket().bind(addr,getAcceptCount()); } else { // Retrieve the channel provided by the OS Channel ic = System.inheritedChannel(); if (ic instanceof ServerSocketChannel) { serverSock = (ServerSocketChannel) ic; } if (serverSock == null) { thrownew IllegalArgumentException(sm.getString("endpoint.init.bind.inherited")); } } serverSock.configureBlocking(true); //mimic APR behavior }
我们可以看到之前文字在源码内部的表达。这里就不多说了。而对于各种中间操作的包装我们该如何去做,依据之前的接口定义,我们应该更注重功能的设定,而无论是filter,flatmap,map等这些常用的操作,其实都是消费动作,理应定义在消费者层面,想到这里,我们该如何去做? 这里,我们就要结合我们的设计模式,装饰模式,对subscribe(Subscriber<? super T> subscriber)所传入的Subscriber进行功能增强,即从Subscriber这个角度来讲,使用的是装饰增强模式,但从外面来看,其整体定义的依然是一个Flux或者Mono,这里FluxArray的话就是例子,这样,从这个角度来讲,其属于向上适配,也就是适配模式,这里的适配玩的比较有意思,完全就是靠对内部类的包装然后通过subscribe(Subscriber<? super T> subscriber)衔接来完成的。
/** *<p>A {@code CountDownLatch} is initialized with a given <em>count</em>. * The {@link #await await} methods block until the current count reaches * zero due to invocations of the {@link #countDown} method, after which * all waiting threads are released and any subsequent invocations of * {@link #await await} return immediately. This is a one-shot phenomenon * -- the count cannot be reset. If you need a version that resets the * count, consider using a {@link CyclicBarrier}. **/
从此处可以知道,CountDownLatch用给定的count进行初始化。 调用await方法会产生阻塞,直到当前计数count由于调用countDown方法而减至零,此后所有等待的线程被释放,并且后续无论是哪个线程再次进行await调用都会立即返回,不会产生其他动作。 也就是说,这是一次性使用的工具,其计数无法重置。 如果你需要重置计数的版本,请考虑使用CyclicBarrier。 这里,我们可以结合下源码来进一步解读,我们首先会看到,CountDownLatch只定义了一个private final Sync sync;字段,其是final类型,一旦赋值就不可变。
CountDownLatch的初始化
我们先来说CountDownLatch的初始化:
1 2 3 4
publicCountDownLatch(int count){ if (count < 0) thrownew IllegalArgumentException("count < 0"); this.sync = new Sync(count); }
/** * Synchronization control For CountDownLatch. * Uses AQS state to represent count. */ privatestaticfinalclassSyncextendsAbstractQueuedSynchronizer{ privatestaticfinallong serialVersionUID = 4982264981922014374L;
protectedbooleantryReleaseShared(int releases){ // Decrement count; signal when transition to zero for (;;) { int c = getState(); if (c == 0) returnfalse; int nextc = c - 1; if (compareAndSetState(c, nextc)) return nextc == 0; } } }
/** * Sets head of queue, and checks if successor may be waiting * in shared mode, if so propagating if either propagate > 0 or * PROPAGATE status was set. * * @param node the node * @param propagate the return value from a tryAcquireShared */ privatevoidsetHeadAndPropagate(Node node, int propagate){ Node h = head; // Record old head for check below setHead(node); if (propagate > 0 || h == null || h.waitStatus < 0 || (h = head) == null || h.waitStatus < 0) { Node s = node.next; if (s == null || s.isShared()) /*之前的节点设定类型在这里就用上了*/ doReleaseShared(); } }
privatevoiddoReleaseShared(){ for (;;) { Node h = head; if (h != null && h != tail) { int ws = h.waitStatus; if (ws == Node.SIGNAL) { if (!h.compareAndSetWaitStatus(Node.SIGNAL, 0)) continue; // loop to recheck cases unparkSuccessor(h); } elseif (ws == 0 && !h.compareAndSetWaitStatus(0, Node.PROPAGATE)) continue; // loop on failed CAS } if (h == head) // loop if head changed break; } }
privatevoidunparkSuccessor(Node node){ /* * If status is negative (i.e., possibly needing signal) try * to clear in anticipation of signalling. It is OK if this * fails or if status is changed by waiting thread. */ int ws = node.waitStatus; if (ws < 0) node.compareAndSetWaitStatus(ws, 0);
/* * Thread to unpark is held in successor, which is normally * just the next node. But if cancelled or apparently null, * traverse backwards from tail to find the actual * non-cancelled successor. */ Node s = node.next; if (s == null || s.waitStatus > 0) { s = null; for (Node p = tail; p != node && p != null; p = p.prev) if (p.waitStatus <= 0) s = p; } if (s != null) LockSupport.unpark(s.thread); }
privatestaticbooleanshouldParkAfterFailedAcquire(Node pred, Node node){ int ws = pred.waitStatus; if (ws == Node.SIGNAL) /* * This node has already set status asking a release * to signal it, so it can safely park. */ returntrue; if (ws > 0) { /* * Predecessor was cancelled. Skip over predecessors and * indicate retry. */ do { node.prev = pred = pred.prev; } while (pred.waitStatus > 0); pred.next = node; } else { /* * waitStatus must be 0 or PROPAGATE. Indicate that we * need a signal, but don't park yet. Caller will need to * retry to make sure it cannot acquire before parking. */ pred.compareAndSetWaitStatus(ws, Node.SIGNAL); } returnfalse; } /** * Convenience method to park and then check if interrupted. * * @return {@code true} if interrupted */ privatefinalbooleanparkAndCheckInterrupt(){ LockSupport.park(this); return Thread.interrupted(); }
javax.persistence.RollbackException: Error while committing the transaction at org.hibernate.ejb.TransactionImpl.commit(TransactionImpl.java:92) at com.sandboxWebapp.hibernate.locking.LockingSample.pessimisticReadWithWrite(LockingSample.java:117) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:44) at org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:15) at org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:41) at org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:20) at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:76) at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:50) at org.junit.runners.ParentRunner$3.run(ParentRunner.java:193) at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:52) at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:191) at org.junit.runners.ParentRunner.access$000(ParentRunner.java:42) at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:184) at org.junit.runners.ParentRunner.run(ParentRunner.java:236) at org.apache.maven.surefire.junit4.JUnit4Provider.execute(JUnit4Provider.java:264) at org.apache.maven.surefire.junit4.JUnit4Provider.executeTestSet(JUnit4Provider.java:153) at org.apache.maven.surefire.junit4.JUnit4Provider.invoke(JUnit4Provider.java:124) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.maven.surefire.util.ReflectionUtils.invokeMethodWithArray2(ReflectionUtils.java:208) at org.apache.maven.surefire.booter.ProviderFactory$ProviderProxy.invoke(ProviderFactory.java:159) at org.apache.maven.surefire.booter.ProviderFactory.invokeProvider(ProviderFactory.java:87) at org.apache.maven.surefire.booter.ForkedBooter.runSuitesInProcess(ForkedBooter.java:153) at org.apache.maven.surefire.booter.ForkedBooter.main(ForkedBooter.java:95) Caused by: javax.persistence.LockTimeoutException: could not execute statement at org.hibernate.ejb.AbstractEntityManagerImpl.wrapLockException(AbstractEntityManagerImpl.java:1440) at org.hibernate.ejb.AbstractEntityManagerImpl.convert(AbstractEntityManagerImpl.java:1339) at org.hibernate.ejb.AbstractEntityManagerImpl.convert(AbstractEntityManagerImpl.java:1310) at org.hibernate.ejb.TransactionImpl.commit(TransactionImpl.java:80) ... 29 more Caused by: org.hibernate.exception.LockTimeoutException: could not execute statement at org.hibernate.dialect.MySQLDialect$1.convert(MySQLDialect.java:408) at org.hibernate.exception.internal.StandardSQLExceptionConverter.convert(StandardSQLExceptionConverter.java:49) at org.hibernate.engine.jdbc.spi.SqlExceptionHelper.convert(SqlExceptionHelper.java:125) at org.hibernate.engine.jdbc.spi.SqlExceptionHelper.convert(SqlExceptionHelper.java:110) at org.hibernate.engine.jdbc.internal.ResultSetReturnImpl.executeUpdate(ResultSetReturnImpl.java:136) at org.hibernate.engine.jdbc.batch.internal.NonBatchingBatch.addToBatch(NonBatchingBatch.java:58) at org.hibernate.persister.entity.AbstractEntityPersister.update(AbstractEntityPersister.java:3238) at org.hibernate.persister.entity.AbstractEntityPersister.updateOrInsert(AbstractEntityPersister.java:3140) at org.hibernate.persister.entity.AbstractEntityPersister.update(AbstractEntityPersister.java:3470) at org.hibernate.action.internal.EntityUpdateAction.execute(EntityUpdateAction.java:140) at org.hibernate.engine.spi.ActionQueue.execute(ActionQueue.java:393) at org.hibernate.engine.spi.ActionQueue.executeActions(ActionQueue.java:385) at org.hibernate.engine.spi.ActionQueue.executeActions(ActionQueue.java:302) at org.hibernate.event.internal.AbstractFlushingEventListener.performExecutions(AbstractFlushingEventListener.java:339) at org.hibernate.event.internal.DefaultFlushEventListener.onFlush(DefaultFlushEventListener.java:52) //请看此处 at org.hibernate.internal.SessionImpl.flush(SessionImpl.java:1240) at org.hibernate.internal.SessionImpl.managedFlush(SessionImpl.java:404) at org.hibernate.engine.transaction.internal.jdbc.JdbcTransaction.beforeTransactionCommit(JdbcTransaction.java:101) at org.hibernate.engine.transaction.spi.AbstractTransactionImpl.commit(AbstractTransactionImpl.java:175) at org.hibernate.ejb.TransactionImpl.commit(TransactionImpl.java:75) ... 29 more Caused by: java.sql.SQLException: Lock wait timeout exceeded; try restarting transaction at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1055) at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:956) at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3491) at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3423) at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:1936) at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2060) at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2542) at com.mysql.jdbc.PreparedStatement.executeInternal(PreparedStatement.java:1734) at com.mysql.jdbc.PreparedStatement.executeUpdate(PreparedStatement.java:2019) at com.mysql.jdbc.PreparedStatement.executeUpdate(PreparedStatement.java:1937) at com.mysql.jdbc.PreparedStatement.executeUpdate(PreparedStatement.java:1922) at org.hibernate.engine.jdbc.internal.ResultSetReturnImpl.executeUpdate(ResultSetReturnImpl.java:133) ... 44 more
/** * File attributes implementation for jrt image file system. * * @implNote This class needs to maintain JDK 8 source compatibility. * * It is used internally in the JDK to implement jimage/jrtfs access, * but also compiled and delivered as part of the jrtfs.jar to support access * to the jimage file provided by the shipped JDK by tools running on JDK 8. */ finalclassJrtFileAttributesimplementsBasicFileAttributes{
@Override public Object fileKey(){ return node.resolveLink(true); }
///////// jrtfs specific attributes /////////// /** * Compressed resource file. If not available or not applicable, 0L is * returned. * * @return the compressed resource size for compressed resources. */ publiclongcompressedSize(){ return node.compressedSize(); }
/** * "file" extension of a file resource. * * @return extension string for the file resource */ public String extension(){ return node.extension(); }
modulesImageExists = AccessController.doPrivileged( new PrivilegedAction<Boolean>() { @Override public Boolean run(){ return Files.isRegularFile(moduleImageFile); } }); }
/** * Returns the appropriate JDK home for this usage of the FileSystemProvider. * When the CodeSource is null (null loader) then jrt:/ is the current runtime, * otherwise the JDK home is located relative to jrt-fs.jar. */ privatestatic String findHome(){ CodeSource cs = SystemImage.class.getProtectionDomain().getCodeSource(); if (cs == null) return System.getProperty("java.home");
// assume loaded from $TARGETJDK/lib/jrt-fs.jar URL url = cs.getLocation(); if (!url.getProtocol().equalsIgnoreCase("file")) thrownew InternalError(url + " loaded in unexpected way"); try { Path lib = Paths.get(url.toURI()).getParent(); if (!lib.getFileName().toString().equals("lib")) thrownew InternalError(url + " unexpected path");
]]>
<h1 id="Refresh-your-Java-skills–聊聊Java9-中模块化所基于的文件系统-JRTFS"><a href="#Refresh-your-Java-skills–聊聊Java9-中模块化所基于的文件系统-JRTFS" class="headerlink" title="Refresh your Java skills–聊聊Java9 中模块化所基于的文件系统 JRTFS"></a>Refresh your Java skills–聊聊Java9 中模块化所基于的文件系统 JRTFS</h1><p>说到文件系统我们很容易就想到Linux,windows操作系统的文件系统,对应到我们的生活中,我们想去一所学校找到某个学生,假如你不了解学号所代表的意义,那就只能是一点一点的找了,不过绝对知道这个学生是几年级,然后一个班一个班的找,假如了解学号的意义的话我们就可以直接定位到哪一栋楼,哪一间教室。</p>
<p>说的再直白点,不就是是个找啊找啊找朋友的游戏么。这也就是我们排序查找的算法了,而面向大量有用数据最好的实践就是用树形结构来统筹,于是我们的数据库的索引,我们的zookeeper的节点管理,小到我们Java里使用的红黑树,以及对hashmap的优化等等,就是因为其复杂度可以降到最低,只需要凭借树的高度就可以快速找到我们所要找的数据了。</p>
<p>说了这么多,就是想要表达的是,我们的Java9中所设计的全新的JRTFS也是基于树来表达的。<br>
Refresh your Java skills--聊聊Java9 中模块化设计是如何实现类似IOC依赖注入效果及与其区别https://muyinchen.github.io/2017/11/07/Refresh your Java skills--聊聊Java9 中模块化设计是如何实现IOC依赖注入效果的/2017-11-07T12:00:25.000Z2017-11-12T08:47:54.812ZRefresh your Java skills–聊聊Java9 中模块化设计是如何实现类似IOC依赖注入效果及与其区别
场景引入
如何实现IOC的效果,我们可以来想想,无非就是一个隐式实现,而想要做到,总不能什么都没有,来个巧妇难为无米之炊的境地吧,所以说,米必须要有滴,在Spring中就是一个bean,也就是说,容器里得有米,再官话点就是上下文中得存在所需要的bean。同样模块化中两个互相隔离的模块想要达到这种效果,也要先往jvm里扔个对象进去的,然后who use ,who get 就可以了。 请看例子(可以认为是我们平常写的SpringMVC项目中的service->serviceImpl->controller):
/** * Creates a new service loader for the given service type, using the * current thread's {@linkplain java.lang.Thread#getContextClassLoader * context class loader}. * * <p> An invocation of this convenience method of the form * <pre>{@code * ServiceLoader.load(service) * }</pre> * * is equivalent to * * <pre>{@code * ServiceLoader.load(service, Thread.currentThread().getContextClassLoader()) * }</pre> * * @apiNote Service loader objects obtained with this method should not be * cached VM-wide. For example, different applications in the same VM may * have different thread context class loaders. A lookup by one application * may locate a service provider that is only visible via its thread * context class loader and so is not suitable to be located by the other * application. Memory leaks can also arise. A thread local may be suited * to some applications. * * @param <S> the class of the service type * * @param service * The interface or abstract class representing the service * * @return A new service loader * * @throws ServiceConfigurationError * if the service type is not accessible to the caller or the * caller is in an explicit module and its module descriptor does * not declare that it uses {@code service} * * @revised 9 * @spec JPMS */ @CallerSensitive publicstatic <S> ServiceLoader<S> load(Class<S> service){ ClassLoader cl = Thread.currentThread().getContextClassLoader(); returnnew ServiceLoader<>(Reflection.getCallerClass(), service, cl); }
publicfinalclassServiceLoader<S> implementsIterable<S> { // The class or interface representing the service being loaded privatefinal Class<S> service;
// The class of the service type privatefinal String serviceName;
// The module layer used to locate providers; null when locating // providers using a class loader privatefinal ModuleLayer layer;
// The class loader used to locate, load, and instantiate providers; // null when locating provider using a module layer privatefinal ClassLoader loader;
// The access control context taken when the ServiceLoader is created privatefinal AccessControlContext acc;
// The lazy-lookup iterator for iterator operations private Iterator<Provider<S>> lookupIterator1; privatefinal List<S> instantiatedProviders = new ArrayList<>();
// The lazy-lookup iterator for stream operations private Iterator<Provider<S>> lookupIterator2; privatefinal List<Provider<S>> loadedProviders = new ArrayList<>(); privateboolean loadedAllProviders; // true when all providers loaded
// Incremented when reload is called privateint reloadCount;
/** * Returns an iterator to iterate over the implementations of {@code * service} in modules defined to the given class loader or in custom * layers with a module defined to this class loader. */ private Iterator<ServiceProvider> iteratorFor(ClassLoader loader){ // modules defined to the class loader ServicesCatalog catalog; if (loader == null) { catalog = BootLoader.getServicesCatalog(); } else { catalog = ServicesCatalog.getServicesCatalogOrNull(loader); } //此处往下到我中文标记结束就是我们的正主了 List<ServiceProvider> providers; if (catalog == null) { providers = List.of(); } else { providers = catalog.findServices(serviceName); } //结束
// modules in layers that define modules to the class loader ClassLoader platformClassLoader = ClassLoaders.platformClassLoader(); if (loader == null || loader == platformClassLoader) { return providers.iterator(); } else { List<ServiceProvider> allProviders = new ArrayList<>(providers); Iterator<ModuleLayer> iterator = LANG_ACCESS.layers(loader).iterator(); while (iterator.hasNext()) { ModuleLayer layer = iterator.next(); for (ServiceProvider sp : providers(layer)) { ClassLoader l = loaderFor(sp.module()); if (l != null && l != platformClassLoader) { allProviders.add(sp); } } } return allProviders.iterator(); } }
这里终于找到了findServices(String service)这个方法:
1 2 3 4 5 6 7
/** * Returns the (possibly empty) list of service providers that implement * the given service type. */ public List<ServiceProvider> findServices(String service){ return map.getOrDefault(service, Collections.emptyList()); }
结合getOrDefault的源码可知:
1 2 3 4 5 6
default V getOrDefault(Object key, V defaultValue){ V v; return (((v = get(key)) != null) || containsKey(key)) ? v : defaultValue; }
/** * Updates module m to provide a service */ publicstaticvoidaddProvides(Module m, Class<?> service, Class<?> impl){ ModuleLayer layer = m.getLayer();
PrivilegedAction<ClassLoader> pa = m::getClassLoader; ClassLoader loader = AccessController.doPrivileged(pa);
/** * The Java side of the JPLIS implementation. Works in concert with a native JVMTI agent * to implement the JPLIS API set. Provides both the Java API implementation of * the Instrumentation interface and utility Java routines to support the native code. * Keeps a pointer to the native data structure in a scalar field to allow native * processing behind native methods. */ publicclassInstrumentationImplimplementsInstrumentation{ ... @Override publicvoidredefineModule(Module module, Set<Module> extraReads, Map<String, Set<Module>> extraExports, Map<String, Set<Module>> extraOpens, Set<Class<?>> extraUses, Map<Class<?>, List<Class<?>>> extraProvides) { if (!module.isNamed()) return;
if (!isModifiableModule(module)) thrownew UnmodifiableModuleException(module.getName());
// copy and check reads extraReads = new HashSet<>(extraReads); if (extraReads.contains(null)) thrownew NullPointerException("'extraReads' contains null");
// copy and check exports and opens extraExports = cloneAndCheckMap(module, extraExports); extraOpens = cloneAndCheckMap(module, extraOpens);
// copy and check uses extraUses = new HashSet<>(extraUses); if (extraUses.contains(null)) thrownew NullPointerException("'extraUses' contains null");
// copy and check provides Map<Class<?>, List<Class<?>>> tmpProvides = new HashMap<>(); for (Map.Entry<Class<?>, List<Class<?>>> e : extraProvides.entrySet()) { Class<?> service = e.getKey(); if (service == null) thrownew NullPointerException("'extraProvides' contains null"); List<Class<?>> providers = new ArrayList<>(e.getValue()); if (providers.isEmpty()) thrownew IllegalArgumentException("list of providers is empty"); providers.forEach(p -> { if (p.getModule() != module) thrownew IllegalArgumentException(p + " not in " + module); if (!service.isAssignableFrom(p)) thrownew IllegalArgumentException(p + " is not a " + service); }); tmpProvides.put(service, providers); } extraProvides = tmpProvides;
/** * This class provides services needed to instrument Java * programming language code. * Instrumentation is the addition of byte-codes to methods for the * purpose of gathering data to be utilized by tools. * Since the changes are purely additive, these tools do not modify * application state or behavior. * Examples of such benign tools include monitoring agents, profilers, * coverage analyzers, and event loggers. * * <P> * There are two ways to obtain an instance of the * <code>Instrumentation</code> interface: * * <ol> * <li><p> When a JVM is launched in a way that indicates an agent * class. In that case an <code>Instrumentation</code> instance * is passed to the <code>premain</code> method of the agent class. * </p></li> * <li><p> When a JVM provides a mechanism to start agents sometime * after the JVM is launched. In that case an <code>Instrumentation</code> * instance is passed to the <code>agentmain</code> method of the * agent code. </p> </li> * </ol> * <p> * These mechanisms are described in the * {@linkplain java.lang.instrument package specification}. * <p> * Once an agent acquires an <code>Instrumentation</code> instance, * the agent may call methods on the instance at any time. * * @since 1.5 */ publicinterfaceInstrumentation{ }
/** * Add a provider in the given module to this services catalog * * @apiNote This method is for use by java.lang.instrument */ publicvoidaddProvider(Module module, Class<?> service, Class<?> impl){ List<ServiceProvider> list = providers(service.getName()); list.add(new ServiceProvider(module, impl.getName())); } ... publicfinalclassServiceProvider{ privatefinal Module module; privatefinal String providerName;
/** * Represents a service provider located by {@code ServiceLoader}. * * <p> When using a loader's {@link ServiceLoader#stream() stream()} method * then the elements are of type {@code Provider}. This allows processing * to select or filter on the provider class without instantiating the * provider. </p> * * @param <S> The service type * @since 9 * @spec JPMS */ publicstaticinterfaceProvider<S> extendsSupplier<S> { /** * Returns the provider type. There is no guarantee that this type is * accessible or that it has a public no-args constructor. The {@link * #get() get()} method should be used to obtain the provider instance. * * <p> When a module declares that the provider class is created by a * provider factory then this method returns the return type of its * public static "{@code provider()}" method. * * @return The provider type */ Class<? extends S> type();
/** * Returns an instance of the provider. * * @return An instance of the provider. * * @throws ServiceConfigurationError * If the service provider cannot be instantiated, or in the * case of a provider factory, the public static * "{@code provider()}" method returns {@code null} or throws * an error or exception. The {@code ServiceConfigurationError} * will carry an appropriate cause where possible. */ @OverrideS get(); }
/** * Returns an iterator to iterate over the implementations of {@code * service} in modules defined to the given class loader or in custom * layers with a module defined to this class loader. */ private Iterator<ServiceProvider> iteratorFor(ClassLoader loader){ // modules defined to the class loader ServicesCatalog catalog; if (loader == null) { catalog = BootLoader.getServicesCatalog(); } else { catalog = ServicesCatalog.getServicesCatalogOrNull(loader); } List<ServiceProvider> providers; if (catalog == null) { providers = List.of(); } else { providers = catalog.findServices(serviceName); } ... }
/** * Implements lazy service provider lookup of service providers that * are provided by modules defined to a class loader or to modules in * layers with a module defined to the class loader. */ privatefinalclassModuleServicesLookupIterator<T> implementsIterator<Provider<T>> { ClassLoader currentLoader; Iterator<ServiceProvider> iterator;
/** * Loads a service provider in a module. * * Returns {@code null} if the service provider's module doesn't read * the module with the service type. * * @throws ServiceConfigurationError if the class cannot be loaded or * isn't the expected sub-type (or doesn't define a provider * factory method that returns the expected type) */ private Provider<S> loadProvider(ServiceProvider provider){ Module module = provider.module(); if (!module.canRead(service.getModule())) { // module does not read the module with the service type returnnull; }
int mods = clazz.getModifiers(); if (!Modifier.isPublic(mods)) { fail(service, clazz + " is not public"); }
// if provider in explicit module then check for static factory method if (inExplicitModule(clazz)) { Method factoryMethod = findStaticProviderMethod(clazz); if (factoryMethod != null) { Class<?> returnType = factoryMethod.getReturnType(); if (!service.isAssignableFrom(returnType)) { fail(service, factoryMethod + " return type not a subtype"); }
/** * A Provider implementation that supports invoking, with reduced * permissions, the static factory to obtain the provider or the * provider's no-arg constructor. */ privatestaticclassProviderImpl<S> implementsProvider<S> { final Class<S> service; final Class<? extends S> type; final Method factoryMethod; // factory method or null final Constructor<? extends S> ctor; // public no-args constructor or null final AccessControlContext acc;
/** * Simple task executor interface that abstracts the execution * of a {@link Runnable}. * * <p>Implementations can use all sorts of different execution strategies, * such as: synchronous, asynchronous, using a thread pool, and more. * * <p>Equivalent to JDK 1.5's {@link java.util.concurrent.Executor} * interface; extending it now in Spring 3.0, so that clients may declare * a dependency on an Executor and receive any TaskExecutor implementation. * This interface remains separate from the standard Executor interface * mainly for backwards compatibility with JDK 1.4 in Spring 2.x. * * @author Juergen Hoeller * @since 2.0 * @see java.util.concurrent.Executor */ @FunctionalInterface publicinterfaceTaskExecutorextendsExecutor{
/** * Execute the given {@code task}. * <p>The call might return immediately if the implementation uses * an asynchronous execution strategy, or might block in the case * of synchronous execution. * @param task the {@code Runnable} to execute (never {@code null}) * @throws TaskRejectedException if the given task was not accepted */ @Override voidexecute(Runnable task);
}
相对来说,org.springframework.scheduling.TaskScheduler接口就有点复杂了。它定义了一组以schedule开头的名称的方法允许我们定义将来要执行的任务。所有 schedule* 方法返回java.util.concurrent.ScheduledFuture实例。Spring5中对scheduleAtFixedRate方法做了进一步的充实,其实最终调用的还是ScheduledFuture<?> scheduleAtFixedRate(Runnable task, long period);
publicinterfaceTaskScheduler{ /** * Schedule the given {@link Runnable}, invoking it whenever the trigger * indicates a next execution time. * <p>Execution will end once the scheduler shuts down or the returned * {@link ScheduledFuture} gets cancelled. * @param task the Runnable to execute whenever the trigger fires * @param trigger an implementation of the {@link Trigger} interface, * e.g. a {@link org.springframework.scheduling.support.CronTrigger} object * wrapping a cron expression * @return a {@link ScheduledFuture} representing pending completion of the task, * or {@code null} if the given Trigger object never fires (i.e. returns * {@code null} from {@link Trigger#nextExecutionTime}) * @throws org.springframework.core.task.TaskRejectedException if the given task was not accepted * for internal reasons (e.g. a pool overload handling policy or a pool shutdown in progress) * @see org.springframework.scheduling.support.CronTrigger */ @Nullable ScheduledFuture<?> schedule(Runnable task, Trigger trigger);
/** * Schedule the given {@link Runnable}, invoking it at the specified execution time. * <p>Execution will end once the scheduler shuts down or the returned * {@link ScheduledFuture} gets cancelled. * @param task the Runnable to execute whenever the trigger fires * @param startTime the desired execution time for the task * (if this is in the past, the task will be executed immediately, i.e. as soon as possible) * @return a {@link ScheduledFuture} representing pending completion of the task * @throws org.springframework.core.task.TaskRejectedException if the given task was not accepted * for internal reasons (e.g. a pool overload handling policy or a pool shutdown in progress) * 使用了默认实现,值得我们学习使用的,Java9中同样可以有私有实现的,从这里我们可以做到我只通过 * 一个接口你来实现,我把其他相应的功能默认实现下,最后调用你自定义实现的接口即可,使接口功能更 * 加一目了然 * @since 5.0 * @see #schedule(Runnable, Date) */ default ScheduledFuture<?> schedule(Runnable task, Instant startTime) { return schedule(task, Date.from(startTime)); } /** * Schedule the given {@link Runnable}, invoking it at the specified execution time. * <p>Execution will end once the scheduler shuts down or the returned * {@link ScheduledFuture} gets cancelled. * @param task the Runnable to execute whenever the trigger fires * @param startTime the desired execution time for the task * (if this is in the past, the task will be executed immediately, i.e. as soon as possible) * @return a {@link ScheduledFuture} representing pending completion of the task * @throws org.springframework.core.task.TaskRejectedException if the given task was not accepted * for internal reasons (e.g. a pool overload handling policy or a pool shutdown in progress) */ ScheduledFuture<?> schedule(Runnable task, Date startTime);
... /** * Schedule the given {@link Runnable}, invoking it at the specified execution time * and subsequently with the given period. * <p>Execution will end once the scheduler shuts down or the returned * {@link ScheduledFuture} gets cancelled. * @param task the Runnable to execute whenever the trigger fires * @param startTime the desired first execution time for the task * (if this is in the past, the task will be executed immediately, i.e. as soon as possible) * @param period the interval between successive executions of the task * @return a {@link ScheduledFuture} representing pending completion of the task * @throws org.springframework.core.task.TaskRejectedException if the given task was not accepted * for internal reasons (e.g. a pool overload handling policy or a pool shutdown in progress) * @since 5.0 * @see #scheduleAtFixedRate(Runnable, Date, long) */ default ScheduledFuture<?> scheduleAtFixedRate(Runnable task, Instant startTime, Duration period) { return scheduleAtFixedRate(task, Date.from(startTime), period.toMillis()); }
/** * Schedule the given {@link Runnable}, invoking it at the specified execution time * and subsequently with the given period. * <p>Execution will end once the scheduler shuts down or the returned * {@link ScheduledFuture} gets cancelled. * @param task the Runnable to execute whenever the trigger fires * @param startTime the desired first execution time for the task * (if this is in the past, the task will be executed immediately, i.e. as soon as possible) * @param period the interval between successive executions of the task (in milliseconds) * @return a {@link ScheduledFuture} representing pending completion of the task * @throws org.springframework.core.task.TaskRejectedException if the given task was not accepted * for internal reasons (e.g. a pool overload handling policy or a pool shutdown in progress) */ ScheduledFuture<?> scheduleAtFixedRate(Runnable task, Date startTime, long period);
public ScheduledFuture<?> schedule(Runnable task, final Trigger trigger) { ManagedScheduledExecutorService executor = (ManagedScheduledExecutorService) scheduledExecutor; return executor.schedule(task, new javax.enterprise.concurrent.Trigger() { @Override public Date getNextRunTime(LastExecution le, Date taskScheduledTime){ return trigger.nextExecutionTime(le != null ? new SimpleTriggerContext(le.getScheduledStart(), le.getRunStart(), le.getRunEnd()) : new SimpleTriggerContext()); } @Override publicbooleanskipRun(LastExecution lastExecution, Date scheduledRunTime){ returnfalse; } }); }
/** * Simple data holder implementation of the {@link TriggerContext} interface. * * @author Juergen Hoeller * @since 3.0 */ publicclassSimpleTriggerContextimplementsTriggerContext{
@Nullable privatevolatile Date lastScheduledExecutionTime;
@Nullable privatevolatile Date lastActualExecutionTime;
@Nullable privatevolatile Date lastCompletionTime; ... /** * Create a SimpleTriggerContext with the given time values. * @param lastScheduledExecutionTime last <i>scheduled</i> execution time * @param lastActualExecutionTime last <i>actual</i> execution time * @param lastCompletionTime last completion time */ publicSimpleTriggerContext(Date lastScheduledExecutionTime, Date lastActualExecutionTime, Date lastCompletionTime){ this.lastScheduledExecutionTime = lastScheduledExecutionTime; this.lastActualExecutionTime = lastActualExecutionTime; this.lastCompletionTime = lastCompletionTime; } ... }
/** * 注释很重要 * An annotation that marks a method to be scheduled. Exactly one of * the {@link #cron()}, {@link #fixedDelay()}, or {@link #fixedRate()} * attributes must be specified. * * <p>The annotated method must expect no arguments. It will typically have * a {@code void} return type; if not, the returned value will be ignored * when called through the scheduler. * * <p>Processing of {@code@Scheduled} annotations is performed by * registering a {@link ScheduledAnnotationBeanPostProcessor}. This can be * done manually or, more conveniently, through the {@code <task:annotation-driven/>} * element or @{@link EnableScheduling} annotation. * * <p>This annotation may be used as a <em>meta-annotation</em> to create custom * <em>composed annotations</em> with attribute overrides. * * @author Mark Fisher * @author Dave Syer * @author Chris Beams * @since 3.0 * @see EnableScheduling * @see ScheduledAnnotationBeanPostProcessor * @see Schedules */ @Target({ElementType.METHOD, ElementType.ANNOTATION_TYPE}) @Retention(RetentionPolicy.RUNTIME) @Documented @Repeatable(Schedules.class) public@interface Scheduled { ... }
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations={"classpath:applicationContext-test.xml"}) @WebAppConfiguration publicclassTaskExecutorsTest{ @Test publicvoidsimpeAsync()throws InterruptedException { /** * SimpleAsyncTaskExecutor creates new Thread for every task and executes it asynchronously. The threads aren't reused as in * native Java's thread pools. * * The number of concurrently executed threads can be specified through concurrencyLimit bean property * (concurrencyLimit XML attribute). Here it's more simple to invoke setConcurrencyLimit method. * Here the tasks will be executed by 2 simultaneous threads. Without specifying this value, * the number of executed threads will be indefinite. * * You can observe that only 2 tasks are executed at a given time - even if 3 are submitted to execution (lines 40-42). **/ SimpleAsyncTaskExecutor executor = new SimpleAsyncTaskExecutor("thread_name_prefix_____"); executor.setConcurrencyLimit(2); executor.execute(new SimpleTask("SimpleAsyncTask-1", Counters.simpleAsyncTask, 1000)); executor.execute(new SimpleTask("SimpleAsyncTask-2", Counters.simpleAsyncTask, 1000)); Thread.sleep(1050); assertTrue("2 threads should be terminated, but "+Counters.simpleAsyncTask.getNb()+" were instead", Counters.simpleAsyncTask.getNb() == 2); executor.execute(new SimpleTask("SimpleAsyncTask-3", Counters.simpleAsyncTask, 1000)); executor.execute(new SimpleTask("SimpleAsyncTask-4", Counters.simpleAsyncTask, 1000)); executor.execute(new SimpleTask("SimpleAsyncTask-5", Counters.simpleAsyncTask, 2000)); Thread.sleep(1050); assertTrue("4 threads should be terminated, but "+Counters.simpleAsyncTask.getNb()+" were instead", Counters.simpleAsyncTask.getNb() == 4); executor.execute(new SimpleTask("SimpleAsyncTask-6", Counters.simpleAsyncTask, 1000)); Thread.sleep(1050); assertTrue("6 threads should be terminated, but "+Counters.simpleAsyncTask.getNb()+" were instead", Counters.simpleAsyncTask.getNb() == 6); } @Test publicvoidsyncTaskTest(){ /** * SyncTask works almost as Java's CountDownLatch. In fact, this executor is synchronous with the calling thread. In our case, * SyncTaskExecutor tasks will be synchronous with JUnit thread. It means that the testing thread will sleep 5 * seconds after executing the third task ('SyncTask-3'). To prove that, we check if the total execution time is ~5 seconds. **/ long start = System.currentTimeMillis(); SyncTaskExecutor executor = new SyncTaskExecutor(); executor.execute(new SimpleTask("SyncTask-1", Counters.syncTask, 0)); executor.execute(new SimpleTask("SyncTask-2", Counters.syncTask, 0)); executor.execute(new SimpleTask("SyncTask-3", Counters.syncTask, 0)); executor.execute(new SimpleTask("SyncTask-4", Counters.syncTask, 5000)); executor.execute(new SimpleTask("SyncTask-5", Counters.syncTask, 0)); long end = System.currentTimeMillis(); int execTime = Math.round((end-start)/1000); assertTrue("Execution time should be 5 seconds but was "+execTime+" seconds", execTime == 5); } @Test publicvoidthreadPoolTest()throws InterruptedException { /** * This executor can be used to expose Java's native ThreadPoolExecutor as Spring bean, with the * possibility to set core pool size, max pool size and queue capacity through bean properties. * * It works exactly as ThreadPoolExecutor from java.util.concurrent package. It means that our pool starts * with 2 threads (core pool size) and can be growth until 3 (max pool size). * In additionally, 1 task can be stored in the queue. This task will be treated * as soon as one from 3 threads ends to execute provided task. In our case, we try to execute 5 tasks * in 3 places pool and 1 place queue. So the 5th task should be rejected and TaskRejectedException should be thrown. **/ ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); executor.setCorePoolSize(2); executor.setMaxPoolSize(3); executor.setQueueCapacity(1); executor.initialize(); executor.execute(new SimpleTask("ThreadPoolTask-1", Counters.threadPool, 1000)); executor.execute(new SimpleTask("ThreadPoolTask-2", Counters.threadPool, 1000)); executor.execute(new SimpleTask("ThreadPoolTask-3", Counters.threadPool, 1000)); executor.execute(new SimpleTask("ThreadPoolTask-4", Counters.threadPool, 1000)); boolean wasTre = false; try { executor.execute(new SimpleTask("ThreadPoolTask-5", Counters.threadPool, 1000)); } catch (TaskRejectedException tre) { wasTre = true; } assertTrue("The last task should throw a TaskRejectedException but it wasn't", wasTre); Thread.sleep(3000); assertTrue("4 tasks should be terminated, but "+Counters.threadPool.getNb()+" were instead", Counters.threadPool.getNb()==4); } } classSimpleTaskimplementsRunnable{ private String name; private Counters counter; privateint sleepTime; publicSimpleTask(String name, Counters counter, int sleepTime){ this.name = name; this.counter = counter; this.sleepTime = sleepTime; } @Override publicvoidrun(){ try { Thread.sleep(this.sleepTime); } catch (InterruptedException e) { e.printStackTrace(); } this.counter.increment(); System.out.println("Running task '"+this.name+"' in Thread "+Thread.currentThread().getName()); } @Override public String toString(){ return"Task {"+this.name+"}"; } } enum Counters { simpleAsyncTask(0), syncTask(0), threadPool(0); privateint nb; publicintgetNb(){ returnthis.nb; } publicsynchronizedvoidincrement(){ this.nb++; } privateCounters(int n){ this.nb = n; } }
Running task 'SimpleAsyncTask-1' in Thread thread_name_prefix_____1 Running task 'SimpleAsyncTask-2' in Thread thread_name_prefix_____2 Running task 'SimpleAsyncTask-3' in Thread thread_name_prefix_____3 Running task 'SimpleAsyncTask-4' in Thread thread_name_prefix_____4 Running task 'SimpleAsyncTask-5' in Thread thread_name_prefix_____5 Running task 'SimpleAsyncTask-6' in Thread thread_name_prefix_____6 Running task 'SyncTask-1' in Thread main Running task 'SyncTask-2' in Thread main Running task 'SyncTask-3' in Thread main Running task 'SyncTask-4' in Thread main Running task 'SyncTask-5' in Thread main Running task 'ThreadPoolTask-2' in Thread ThreadPoolTaskExecutor-2 Running task 'ThreadPoolTask-1' in Thread ThreadPoolTaskExecutor-1 Running task 'ThreadPoolTask-4' in Thread ThreadPoolTaskExecutor-3 Running task 'ThreadPoolTask-3' in Thread ThreadPoolTaskExecutor-2
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations={"classpath:applicationContext-test.xml"}) @WebAppConfiguration publicclassAnnotationTest{ @Autowired private GenericApplicationContext context; @Test publicvoidtestScheduled()throws InterruptedException { System.out.println("Start sleeping"); Thread.sleep(6000); System.out.println("Wake up !"); TestScheduledTask scheduledTask = (TestScheduledTask) context.getBean("testScheduledTask"); /** * Test fixed delay. It's executed every 6 seconds. The first execution is registered after application's context start. **/ assertTrue("Scheduled task should be executed 2 times (1 before sleep in this method, 1 after the sleep), but was "+scheduledTask.getFixedDelayCounter(), scheduledTask.getFixedDelayCounter() == 2); /** * Test fixed rate. It's executed every 6 seconds. The first execution is registered after application's context start. * Unlike fixed delay, a fixed rate configuration executes one task with specified time. For example, it will execute on * 6 seconds delayed task at 10:30:30, 10:30:36, 10:30:42 and so on - even if the task 10:30:30 taken 30 seconds to * be terminated. In teh case of fixed delay, if the first task takes 30 seconds, the next will be executed 6 seconds * after the first one, so the execution flow will be: 10:30:30, 10:31:06, 10:31:12. **/ assertTrue("Scheduled task should be executed 2 times (1 before sleep in this method, 1 after the sleep), but was "+scheduledTask.getFixedRateCounter(), scheduledTask.getFixedRateCounter() == 2); /** * Test fixed rate with initial delay attribute. The initialDelay attribute is set to 6 seconds. It causes that * scheduled method is executed 6 seconds after application's context start. In our case, it should be executed * only once because of previous Thread.sleep(6000) invocation. **/ assertTrue("Scheduled task should be executed 1 time (0 before sleep in this method, 1 after the sleep), but was "+scheduledTask.getInitialDelayCounter(), scheduledTask.getInitialDelayCounter() == 1); /** * Test cron scheduled task. Cron is scheduled to be executed every 6 seconds. It's executed only once, * so we can deduce that it's not invoked directly before applications * context start, but only after configured time (6 seconds in our case). **/ assertTrue("Scheduled task should be executed 1 time (0 before sleep in this method, 1 after the sleep), but was "+scheduledTask.getCronCounter(), scheduledTask.getCronCounter() == 1); } @Test publicvoidtestAsyc()throws InterruptedException { /** * To test @Async annotation, we can create a bean in-the-fly. AsyncCounter bean is a * simple counter which value should be equals to 2 at the end of the test. A supplementary test * concerns threads which execute both of AsyncCounter methods: one which * isn't annotated with @Async and another one which is annotated with it. For the first one, invoking * thread should have the same name as the main thread. For annotated method, it can't be executed in * the main thread. It must be executed asynchrounously in a new thread. **/ context.registerBeanDefinition("asyncCounter", new RootBeanDefinition(AsyncCounter.class)); String currentName = Thread.currentThread().getName(); AsyncCounter asyncCounter = context.getBean("asyncCounter", AsyncCounter.class); asyncCounter.incrementNormal(); assertTrue("Thread executing normal increment should be the same as JUnit thread but it wasn't (expected '"+currentName+"', got '"+asyncCounter.getNormalThreadName()+"')", asyncCounter.getNormalThreadName().equals(currentName)); asyncCounter.incrementAsync(); // sleep 50ms and give some time to AsyncCounter to update asyncThreadName value Thread.sleep(50); assertFalse("Thread executing @Async increment shouldn't be the same as JUnit thread but it wasn (JUnit thread '"+currentName+"', @Async thread '"+asyncCounter.getAsyncThreadName()+"')", asyncCounter.getAsyncThreadName().equals(currentName)); System.out.println("Main thread execution's name: "+currentName); System.out.println("AsyncCounter normal increment thread execution's name: "+asyncCounter.getNormalThreadName()); System.out.println("AsyncCounter @Async increment thread execution's name: "+asyncCounter.getAsyncThreadName()); assertTrue("Counter should be 2, but was "+asyncCounter.getCounter(), asyncCounter.getCounter()==2); } } classAsyncCounter{ privateint counter = 0; private String normalThreadName; private String asyncThreadName; publicvoidincrementNormal(){ normalThreadName = Thread.currentThread().getName(); this.counter++; } @Async publicvoidincrementAsync(){ asyncThreadName = Thread.currentThread().getName(); this.counter++; } public String getAsyncThreadName(){ return asyncThreadName; } public String getNormalThreadName(){ return normalThreadName; } publicintgetCounter(){ returnthis.counter; } }
另外,我们需要创建新的配置文件和一个包含定时任务方法的类:
1 2 3 4 5 6 7 8 9 10 11
<!-- imported configuration file first --> <!-- Activates various annotations to be detected in bean classes --> <context:annotation-config /> <!-- Scans the classpath for annotated components that will be auto-registered as Spring beans. For example @Controller and @Service. Make sure to set the correct base-package--> <context:component-scanbase-package="com.migo.test.schedulers" /> <task:schedulerid="taskScheduler"/> <task:executorid="taskExecutor"pool-size="40" /> <task:annotation-drivenexecutor="taskExecutor"scheduler="taskScheduler"/>
// scheduled methods after, all are executed every 6 seconds (scheduledAtFixedRate and scheduledAtFixedDelay start to execute at // application context start, two other methods begin 6 seconds after application's context start) @Component publicclassTestScheduledTask{ privateint fixedRateCounter = 0; privateint fixedDelayCounter = 0; privateint initialDelayCounter = 0; privateint cronCounter = 0; @Scheduled(fixedRate = 6000) publicvoidscheduledAtFixedRate(){ System.out.println("<R> Increment at fixed rate"); fixedRateCounter++; } @Scheduled(fixedDelay = 6000) publicvoidscheduledAtFixedDelay(){ System.out.println("<D> Incrementing at fixed delay"); fixedDelayCounter++; } @Scheduled(fixedDelay = 6000, initialDelay = 6000) publicvoidscheduledWithInitialDelay(){ System.out.println("<DI> Incrementing with initial delay"); initialDelayCounter++; } @Scheduled(cron = "**/6 ** ** ** ** **") publicvoidscheduledWithCron(){ System.out.println("<C> Incrementing with cron"); cronCounter++; } publicintgetFixedRateCounter(){ returnthis.fixedRateCounter; } publicintgetFixedDelayCounter(){ returnthis.fixedDelayCounter; } publicintgetInitialDelayCounter(){ returnthis.initialDelayCounter; } publicintgetCronCounter(){ returnthis.cronCounter; } }
该测试的输出:
1 2 3 4 5 6 7 8 9 10 11
<R> Increment at fixed rate <D> Incrementing at fixed delay Start sleeping <C> Incrementing with cron <DI> Incrementing with initial delay <R> Increment at fixed rate <D> Incrementing at fixed delay Wake up ! Main thread execution's name: main AsyncCounter normal increment thread execution's name: main AsyncCounter @Async increment thread execution's name: taskExecutor-1
同样,我们知道,Java的javac指令不会生成机器代码,而是一些名为字节码的东西。而这不仅仅是一种语言会这么做(而这也是很多现代语言所发展的一个方向)。比如ActionScript(由ActionScript Virtual Machine执行)或CIL(由C#使用并在Common Language Runtime上执行)。
在这里,在我们的括号中所说的“执行”,也就是即时编译完成(即字节码编译成目标机器可执行的机器码)。这种特殊类型的编译发生在解释给定字节码的机器上,如ActionScript虚拟机或Java虚拟机(JVM)。字节码由他们在运行时( on runtime)编译成机器码。
/** * Set a custom executor (typically a {@link org.springframework.core.task.TaskExecutor}) * to invoke each listener with. * <p>Default is equivalent to {@link org.springframework.core.task.SyncTaskExecutor}, * executing all listeners synchronously in the calling thread. * <p>Consider specifying an asynchronous task executor here to not block the * caller until all listeners have been executed. However, note that asynchronous * execution will not participate in the caller's thread context (class loader, * transaction association) unless the TaskExecutor explicitly supports this. * @see org.springframework.core.task.SyncTaskExecutor * @see org.springframework.core.task.SimpleAsyncTaskExecutor * @Nullable 可看出Executor参数可为null,默认不设置的话,上面multicastEvent也就直接 * 跳过异步执行了 */ publicvoidsetTaskExecutor(@Nullable Executor taskExecutor){ this.taskExecutor = taskExecutor; }
/** * Return the current task executor for this multicaster. */ @Nullable protected Executor getTaskExecutor(){ returnthis.taskExecutor; }
/** * Executes the given task, within a concurrency throttle * if configured (through the superclass's settings). * @see #doExecute(Runnable) */ @Override publicvoidexecute(Runnable task){ execute(task, TIMEOUT_INDEFINITE); }
/** * Executes the given task, within a concurrency throttle * if configured (through the superclass's settings). * <p>Executes urgent tasks (with 'immediate' timeout) directly, * bypassing the concurrency throttle (if active). All other * tasks are subject to throttling. * @see #TIMEOUT_IMMEDIATE * @see #doExecute(Runnable) */ @Override publicvoidexecute(Runnable task, long startTimeout){ Assert.notNull(task, "Runnable must not be null"); Runnable taskToUse = (this.taskDecorator != null ? this.taskDecorator.decorate(task) : task); if (isThrottleActive() && startTimeout > TIMEOUT_IMMEDIATE) { this.concurrencyThrottle.beforeAccess(); doExecute(new ConcurrencyThrottlingRunnable(taskToUse)); } else { doExecute(taskToUse); } }
@Override public Future<?> submit(Runnable task) { //创建 FutureTask<Object> future = new FutureTask<>(task, null); //执行 execute(future, TIMEOUT_INDEFINITE); return future; }
@Override public <T> Future<T> submit(Callable<T> task){ FutureTask<T> future = new FutureTask<>(task); execute(future, TIMEOUT_INDEFINITE); return future; } /** * Template method for the actual execution of a task. * <p>The default implementation creates a new Thread and starts it. * @param task the Runnable to execute * @see #setThreadFactory * @see #createThread * @see java.lang.Thread#start() */ protectedvoiddoExecute(Runnable task){ Thread thread = (this.threadFactory != null ? this.threadFactory.newThread(task) : createThread(task)); //可以看出,执行也只是简单的将创建的线程start执行下,别提什么重用了 thread.start(); }
/** * 下面的注释意思很明显了,不多说了 * {@link TaskExecutor} implementation that executes each task <i>synchronously</i> * in the calling thread. * * <p>Mainly intended for testing scenarios. * * <p>Execution in the calling thread does have the advantage of participating * in it's thread context, for example the thread context class loader or the * thread's current transaction association. That said, in many cases, * asynchronous execution will be preferable: choose an asynchronous * {@code TaskExecutor} instead for such scenarios. * * @author Juergen Hoeller * @since 2.0 * @see SimpleAsyncTaskExecutor */ @SuppressWarnings("serial") publicclassSyncTaskExecutorimplementsTaskExecutor, Serializable{
/** * Executes the given {@code task} synchronously, through direct * invocation of it's {@link Runnable#run() run()} method. * @throws IllegalArgumentException if the given {@code task} is {@code null} */ @Override publicvoidexecute(Runnable task){ Assert.notNull(task, "Runnable must not be null"); task.run(); }
}
首先,我们需要为我们的测试用例添加一些bean:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
<bean id="syncTaskExecutor"class="org.springframework.core.task.SyncTaskExecutor" /> <bean id="asyncTaskExecutor"class="org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor"> <!-- 10 task will be submitted immediately --> <property name="corePoolSize" value="10" /> <!-- If 10 task are already submitted and treated, we allow to enlarge pool capacity to 15 (10 from core pool size + 5 from max pool size) --> <property name="maxPoolSize" value="15" /> <!-- Number of tasks that can be placed into waiting queue --> <property name="queueCapacity" value="10" /> </bean> <bean id="applicationEventMulticaster"class="com.migo.event.SimpleEventMulticaster"> <property name="taskExecutor" ref="syncTaskExecutor" /> <property name="asyncTaskExecutor" ref="asyncTaskExecutor" /> </bean> <bean id="taskStatsHolder"class="com.migo.event.TaskStatsHolder" />
// ProductChangeFailureEvent.java /** * This is synchronous event dispatched when one product is modified in the backoffice. * When product's modification fails (database, validation problem), this event is dispatched to * all listeners. It's synchronous because we want to inform the user that some actions were done * after the failure. Otherwise (asynchronous character of event) we shouldn't be able to * know if something was done or not after the dispatch. **/ publicclassProductChangeFailureEventextendsApplicationContextEvent{ privatestaticfinallong serialVersionUID = -1681426286796814792L; publicstaticfinal String TASK_KEY = "ProductChangeFailureEvent"; publicProductChangeFailureEvent(ApplicationContext source){ super(source); } } // NotifMailDispatchEvent.java /** * Event dispatched asynchronously every time when we want to send a notification mail. * Notification mails to send should be stored somewhere (filesystem, database...) but in * our case, we'll handle only one notification mail: when one product out-of-stock becomes available again. **/ publicclassNotifMailDispatchEventextendsApplicationContextEventimplementsAsyncApplicationEvent{ privatestaticfinallong serialVersionUID = 9202282810553100778L; publicstaticfinal String TASK_KEY = "NotifMailDispatchEvent"; publicNotifMailDispatchEvent(ApplicationContext source){ super(source); } }
// ProductChangeFailureListener.java @Component publicclassProductChangeFailureListener implementsApplicationListener<ProductChangeFailureEvent>{ @Override publicvoidonApplicationEvent(ProductChangeFailureEvent event){ long start = System.currentTimeMillis(); long end = System.currentTimeMillis(); ((TaskStatsHolder) event.getApplicationContext().getBean("taskStatsHolder")).addNewTaskStatHolder(ProductChangeFailureEvent.TASK_KEY, new TaskStatData(Thread.currentThread().getName(), start, end)); } } // NotifMailDispatchListener.java @Component publicclassNotifMailDispatchListener implementsApplicationListener<NotifMailDispatchEvent>{ @Override publicvoidonApplicationEvent(NotifMailDispatchEvent event)throws InterruptedException { long start = System.currentTimeMillis(); // sleep 5 seconds to avoid that two listeners execute at the same moment Thread.sleep(5000); long end = System.currentTimeMillis(); ((TaskStatsHolder) event.getApplicationContext().getBean("taskStatsHolder")).addNewTaskStatHolder(NotifMailDispatchEvent.TASK_KEY, new TaskStatData(Thread.currentThread().getName(), start, end)); } }
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations={"classpath:applicationContext-test.xml"}) @WebAppConfiguration publicclassSpringSyncAsyncEventsTest{ @Autowired private WebApplicationContext wac; @Test publicvoidtest(){ MockMvc mockMvc = MockMvcBuilders.webAppContextSetup(this.wac).build(); // execute both urls simultaneously mockMvc.perform(get("/products/change-success")); mockMvc.perform(get("/products/change-failure")); // get stats holder and check if both stats are available: // - mail dispatching shouldn't be available because it's executed after a sleep of 5 seconds // - product failure should be available because it's executed synchronously, almost immediately (no operations in listeners) TaskStatsHolder statsHolder = (TaskStatsHolder) this.wac.getBean("taskStatsHolder"); TaskStatData mailStatData = statsHolder.getTaskStatHolder(NotifMailDispatchEvent.TASK_KEY); TaskStatData productFailureData = statsHolder.getTaskStatHolder(ProductChangeFailureEvent.TASK_KEY); assertTrue("Task for mail dispatching is executed after 5 seconds, so at this moment, it taskStatsHolder shouldn't contain it", mailStatData == null); assertTrue("productFailureHolder shouldn't be null but it is", productFailureData != null); assertTrue("Product failure listener should be executed within 0 seconds but took "+productFailureData.getExecutionTime()+" seconds", productFailureData.getExecutionTime() == 0); while (mailStatData == null) { mailStatData = statsHolder.getTaskStatHolder(NotifMailDispatchEvent.TASK_KEY); } // check mail dispatching stats again, when available assertTrue("Now task for mail dispatching should be at completed state", mailStatData != null); assertTrue("Task for mail dispatching should take 5 seconds but it took "+mailStatData.getExecutionTime()+" seconds", mailStatData.getExecutionTime() == 5); assertTrue("productFailureHolder shouldn't be null but it is", productFailureData != null); assertTrue("Product failure listener should be executed within 0 seconds but took "+productFailureData.getExecutionTime()+" seconds", productFailureData.getExecutionTime() == 0); assertTrue("Thread executing mail dispatch and product failure listeners shouldn't be the same", !productFailureData.getThreadName().equals(mailStatData.getThreadName())); assertTrue("Thread executing product failure listener ("+productFailureData.getThreadName()+") should be the same as current thread ("+Thread.currentThread().getName()+") but it wasn't", Thread.currentThread().getName().equals(productFailureData.getThreadName())); assertTrue("Thread executing mail dispatch listener ("+mailStatData.getThreadName()+") shouldn't be the same as current thread ("+Thread.currentThread().getName()+") but it was", !Thread.currentThread().getName().equals(mailStatData.getThreadName())); // make some output to see the informations about tasks System.out.println("Data about mail notif dispatching event: "+mailStatData); System.out.println("Data about product failure dispatching event: "+productFailureData); } }
Product was correctly changed I'm modifying the product but a NullPointerException will be thrown Data about mail notif dispatching event: TaskStatData {thread name: asyncTaskExecutor-1(异步线程), start time: Thu Jun 19 21:14:18 CEST 2016, end time: Thu Jun 19 21:14:23 CEST 2016, execution time: 5 seconds} Data about product failure dispatching event: TaskStatData {thread name: main(主线程), start time: Thu Jun 19 21:14:21 CEST 2016, end time: Thu Jun 19 21:14:21 CEST 2016, execution time: 0 seconds}